03 数组中重复的数字
题目
在一个长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。
class Solution {
public int findRepeatNumber(int[] nums) {
}
}题解
基本思路
初步想法是创建一个Set,然后遍历数组并把数字添加入Set,每次添加的时候如果数字已经存在,就返回该数字。
但是这样的话时间复杂度和空间复杂度太高了。
public class Solution {
public int findRepeatNumber(int[] nums) {
Set<Integer> set = new HashSet<Integer>();
int repeat = -1;
for (int num : nums) {
if (!set.add(num)) {
repeat = num;
break;
}
}
return repeat;
}
}执行用时:4 ms, 在所有 Java 提交中击败了53.18%的用户
内存消耗:48.4 MB, 在所有 Java 提交中击败了8.69%的用户
优化思路
用数组代替set
此时注意到题目中说所有数字都在0到n-1之间,那只需要构建一个长度为n的数组map,数组中每个元素的初始值为0;
然后遍历nums数组,每次遍历到的值就是map数组中对应的下标,让其+1;
如果map中有某个下标的值>1,则说明有重复。
public class Solution {
public int findRepeatNumber(int[] nums) {
int[] map = new int[nums.length];
for (int num : nums) {
map[num]++;
if (map[num] > 1)
return num;
}
return -1;
}
}执行用时:1 ms, 在所有 Java 提交中击败了81.07%的用户
内存消耗:46 MB, 在所有 Java 提交中击败了78.04%的用户
时间复杂度O(n)
空间复杂度O(n)
虽然与set同是O(n),但是性能还是提高了
原地交换
由于nums长度为n,其中数字也是0到n-1,所以其中每个数字可以有一个对应的下标;
要进行的操作就是遍历nums,然后把每个数字与对应下标位置的数字交换;
如果对应下标处已经有一个相同的值,则说明重复了。
public class Solution {
public int findRepeatNumber(int[] nums) {
int i = 0;
while (i < nums.length) {
int cur = nums[i];//当前位置的值
//如果当前位置的值等于i,则不需要进行操作
if (cur == i) {
i++;
//这个地方很关键,只有当一个元素被放到正确的位置才让i+1
//可以保证当前位置数字和目标位置数字交换时,目标位置的数字会被放到当前位置,继续交换,而不是被跳过
continue;
}
//nums[cur]表示要交换的目标位置
//如果目标位置已经有一个相等的值,则表示重复
if (nums[cur] == cur)
return cur;
int temp = cur;
nums[i] = nums[cur];
nums[cur] = temp;
}
return -1;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:46 MB, 在所有 Java 提交中击败了84.17%的用户
时间O(n)
空间O(1)
04 二维数组中的查找
题目
在一个 n * m 的二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个高效的函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
class Solution {
public boolean findNumberIn2DArray(int[][] matrix, int target) {
}
}示例:
现有矩阵 matrix 如下:
[
[1, 4, 7, 11, 15],
[2, 5, 8, 12, 19],
[3, 6, 9, 16, 22],
[10, 13, 14, 17, 24],
[18, 21, 23, 26, 30]
]给定 target = 5,返回 true。
给定 target = 20,返回 false。
题解
暴力解法就不说了。
本来想用一维数组中的二分查找的方法来写这道题,但是写着写着人就麻了;
后来参考力扣的题解,发现了一种不错的方法。
大致思路:
从二维数组的右上角开始遍历;
如果当前数字比target小,就向下移动一格;
如果当前数字比target大,就向前移动一格;
由于从右上角开始,左边的数一定比这个位置小,下边的数一定比这个位置大,因此一定不会错过目标值。
public class Solution {
public boolean findNumberIn2DArray(int[][] matrix, int target) {
if (matrix == null || matrix.length == 0 || matrix[0].length == 0) return false;
int rows = 0;
int columns = matrix[0].length - 1;
while (rows <= matrix.length - 1 && columns >= 0) {
if (matrix[rows][columns] > target)
columns--;
else if (matrix[rows][columns] < target)
rows++;
else if (matrix[rows][columns] == target)
return true;
}
return false;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:44.2 MB, 在所有 Java 提交中击败了49.71%的用户
05 替换空格
题目
请实现一个函数,把字符串 s 中的每个空格替换成”%20″。
class Solution {
public String replaceSpace(String s) {
}
}题解
基本思路
创建一个StringBuilder,然后遍历原字符串,遇到其他字符原样append(),遇到空格则append(“%20”)
public class Solution {
public String replaceSpace(String s) {
StringBuilder stringBuilder = new StringBuilder();
for (int i = 0; i < s.length(); i++) {
char cur = s.charAt(i);
if (cur != ' ') {
stringBuilder.append(cur);
} else {
stringBuilder.append("%20");
}
}
return stringBuilder.toString();
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:35.9 MB, 在所有 Java 提交中击败了97.71%的用户
还有一种思路是创建一个s三倍长度的字符数组来操作,也是可以的
06 从尾到头打印链表
题目
输入一个链表的头节点,从尾到头反过来返回每个节点的值(用数组返回)。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public int[] reversePrint(ListNode head) {
}
}题解
初步思路
初步思路是定义一个List,储存每一个节点的值,最后反转一下
public class Solution {
public int[] reversePrint(ListNode head) {
List<Integer> list = new ArrayList<>();
while (head.next != null) {
list.add(head.val);
head = head.next;
}
Collections.reverse(list);
return list.stream().mapToInt(Integer::valueOf).toArray();
}
}执行用时:3 ms, 在所有 Java 提交中击败了6.82%的用户
内存消耗:39 MB, 在所有 Java 提交中击败了47.28%的用户
这耗时确实铸币了。。。。
优化
用一个栈来实现反转
public class Solution {
public int[] reversePrint(ListNode head) {
Stack<Integer> stack = new Stack<>();
while (head != null) {
stack.push(head.val);
head = head.next;
}
int[] res = new int[stack.size()];
int pointer = 0;
while (!stack.isEmpty()) {
res[pointer++] = stack.pop();
}
return res;
}
}执行用时:1 ms, 在所有 Java 提交中击败了73.77%的用户
内存消耗:39.1 MB, 在所有 Java 提交中击败了41.07%的用户
07 重建二叉树
题目
输入某二叉树的前序遍历和中序遍历的结果,请构建该二叉树并返回其根节点。
假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode buildTree(int[] preorder, int[] inorder) {
}
}示例:

Input: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
Output: [3,9,20,null,null,15,7]Input: preorder = [-1], inorder = [-1]
Output: [-1]题解
分治
大致过程
前序遍历性质: 节点按照 [ 根节点 | 左子树 | 右子树 ] 排序。
中序遍历性质: 节点按照 [ 左子树 | 根节点 | 右子树 ] 排序。
根据这两个性质,可以有以下推论:
1、前序遍历的第一个元素是树的根节点
2、根据推论1又可以找到中序遍历数组中的根节点的位置,从而将其划分为[ 左子树 | 根节点 | 右子树 ]
3、根据推论2可以知道中序遍历中左/右子树节点的节点数量,从而将前序遍历数组划分为[ 根节点 | 左子树 | 右子树 ]
通过1,2,3推论,可以确定出三个节点:树的根节点、左子树的根节点、右子树的根节点
对于树的左/右子树,可以再次使用上述步骤确定点。
详细思路
前序遍历
| 根节点 | 左子树 | 右子树 |
|---|---|---|
| 3 | 9 | 20,15,7 |
中序遍历
| 左子树 | 根节点 | 右子树 |
|---|---|---|
| 9 | 3 | 15,20,7 |
重建一棵二叉树,需要三个点(用索引表示):
1、根节点root:前序遍历中的第一个点
2、左节点left:前序遍历中左子树的第一个点,即left=root+1
3、右节点right:前序遍历中右子树的第一个点,等于root+左子树的长度+1
左子树的长度=中序遍历中根节点的索引-中序遍历的左边界
public class Solution {
//前序遍历性质: 节点按照 [ 根节点 | 左子树 | 右子树 ] 排序。
//中序遍历性质: 节点按照 [ 左子树 | 根节点 | 右子树 ] 排序。
//用map存中序遍历的数组的指对应的索引,方便找到某个数在中序数组中的下标
HashMap<Integer, Integer> map = new HashMap<>();
//保存一下前序遍历的数组,主要是方便传参
int[] preorder;
public TreeNode buildTree(int[] preorder, int[] inorder) {
this.preorder = preorder;
for (int i = 0; i < inorder.length; i++) {
map.put(inorder[i], i);
}
//第一个参数:当前根节点在前序遍历中的索引
//第二个参数:当前树在中序遍历中的左边界
//第三个参数:当前树在中序遍历中的右边界
return rebuild(0, 0, inorder.length - 1);
}
public TreeNode rebuild(int root, int left, int right) {
if (left > right) return null;
//建立根节点
TreeNode node = new TreeNode(preorder[root]);
//找到根节点在中序遍历中的下标位置
int i = map.get(preorder[root]);
//找node的左节点,即左子树的根节点
//根节点索引是前序遍历中 左子树 部分的第一个,也就是root+1
//左边界不变,右边界为根节点在中序遍历的索引-1,因为进入这个分治递归后,主体是左子树
node.left = rebuild(root + 1, left, i - 1);
//找node的右节点,即右子树的根节点
//根节点索引是前序遍历中 右子树部分的第一个,也就是root+i+1
//左边界是中序遍历中右子树的第一个,也就是i+1,右边界不变
node.right = rebuild(root + (i - left) + 1, i + 1, right);
return node;
}
}执行用时:2 ms, 在所有 Java 提交中击败了96.38%的用户
内存消耗:38.1 MB, 在所有 Java 提交中击败了92.77%的用户
09 双栈实现队列
题目
用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead 操作返回 -1 )
class CQueue {
public CQueue() {
}
public void appendTail(int value) {
}
public int deleteHead() {
}
}题解
初步思路
这道题思路很简单,我们定义两个栈分别叫stack1和stack2;
当在尾部插入元素事,就push进stack1,要删除头部元素时,就将stack1一个个pop并push入stack2,此时stack2的栈顶元素就是一开始的队列头部元素,将其pop后再把stack2还原入stack1即可。
public class CQueue {
Stack<Integer> stack1;
Stack<Integer> stack2;
public CQueue() {
stack1 = new Stack<>();
stack2 = new Stack<>();
}
public void appendTail(int value) {
stack1.push(value);
}
public int deleteHead() {
int num = -1;
while (!stack1.isEmpty()) {
stack2.push(stack1.pop());
}
if (!stack2.isEmpty())
num = stack2.pop();
while (!stack2.isEmpty()) {
stack1.push(stack2.pop());
}
return num;
}
}执行用时:233 ms, 在所有 Java 提交中击败了8.27%的用户
内存消耗:46.6 MB, 在所有 Java 提交中击败了61.03%的用户
可以看到时间复杂度有些高了。
优化
主要时间复杂度出在删除头部元素这个方法;
我们每次通过stack2把头部元素删除后,又重新把stack2还原回了stack1,其实这一步是没必要的;
只要stack2不为空,那么stack2栈顶的元素始终是头部元素。
根据这个思路我们可以优化一下代码:
public class CQueue {
Stack<Integer> stack1;
Stack<Integer> stack2;
public CQueue() {
stack1 = new Stack<>();
stack2 = new Stack<>();
}
public void appendTail(int value) {
stack1.push(value);
}
public int deleteHead() {
if (stack2.isEmpty()) {
if (stack1.isEmpty())
return -1;
while (!stack1.isEmpty()) {
stack2.push(stack1.pop());
}
}
return stack2.pop();
}
}执行用时:43 ms, 在所有 Java 提交中击败了79.66%的用户
内存消耗:46.6 MB, 在所有 Java 提交中击败了61.50%的用户
10 I 斐波那契数列
题目
写一个函数,输入 n ,求斐波那契(Fibonacci)数列的第 n 项(即 F(N))。斐波那契数列的定义如下:
F(0) = 0, F(1) = 1
F(N) = F(N – 1) + F(N – 2), 其中 N > 1.
斐波那契数列由 0 和 1 开始,之后的斐波那契数就是由之前的两数相加而得出。
答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。
class Solution {
public int fib(int n) {
}
}示例 1:
输入:n = 2
输出:1示例 2:
输入:n = 5
输出:5题解
初步思路
简单的动态规划,但是有几个小细节
public class Solution {
public int fib(int n) {
if (n == 0) return 0;
int[] dp = new int[n + 1];
//新建数组大小是n+1,因为输入的n表示的第n项是从1开始的
dp[0] = 0;
dp[1] = 1;
for (int i = 2; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
dp[i] %= 1000000007;
//取模,不光是题目要求,也是为了防止越界
}
return dp[n];
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:35.3 MB, 在所有 Java 提交中击败了25.87%的用户
优化
其实类似的动态规划的优化思路都相似;
由状态转移方程dp[n] = dp[n - 1] + dp[n - 2]可知,每一步要求得dp[n]其实只是要知道前两个位置的值就可以了,因此没必要创建n+1大小的数组。
这种优化有几个细节需要注意。
public class Solution {
public int fib(int n) {
int a = 0, b = 1, sum = 0;
//a相当于F(0),b相当于F(1);
if (n == 1) return 1;
//要计算出F(n),只要循环n-1次,
//因为sum一开始就是a+b,相当于已经算过F(1)了
//也正是因为如此,上面需要特判一下n=1的情况
for (int i = 0; i < n - 1; i++) {
sum = (a + b) % 1000000007;
a = b;
b = sum;
}
return sum;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:35.2 MB, 在所有 Java 提交中击败了54.16%的用户
10 II 青蛙跳台阶问题
题目
一只青蛙一次可以跳上1级台阶,也可以跳上2级台阶。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。
class Solution {
public int numWays(int n) {
}
}示例 1:
输入:n = 2
输出:2示例 2:
输入:n = 7
输出:21示例 3:
输入:n = 0
输出:1提示:
0 <= n <= 100
题解
初步思路
其实这题和10II一模一样
创建一个数组dp,dp[n]表示跳上第n级有多少种跳法
状态转移方程:dp[n]=dp[n-1]+dp[n-2]
public class Solution {
public int numWays(int n) {
if (n == 0) return 1;
int[] dp = new int[n + 1];
dp[0] = 1;
dp[1] = 1;
for (int i = 2; i <= n; i++) {
dp[i] = dp[i - 1] + dp[i - 2];
dp[i] %= 1000000007;
}
return dp[n];
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:35.3 MB, 在所有 Java 提交中击败了26.45%的用户
优化
其实类似的动态规划的优化思路都相似;
由状态转移方程dp[n] = dp[n - 1] + dp[n - 2]可知,每一步要求得dp[n]其实只是要知道前两个位置的值就可以了,因此没必要创建n+1大小的数组。
这种优化有几个细节需要注意。
public class Solution {
public int numWays(int n) {
if (n == 1) return 1;
int a = 1, b = 1, c = 1;
//c初始化成n=0的情况,这样就免去了n=0的特判
/
for (int i = 0; i < n - 1; i++) {
c = (a + b) % 1000000007;
a = b;
b = c;
}
return c;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:35.1 MB, 在所有 Java 提交中击败了63.06%的用户
11 旋转数组的最小数字
tag:
题目
把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个递增排序的数组的一个旋转,输出旋转数组的最小元素。例如,数组 [3,4,5,1,2] 为 [1,2,3,4,5] 的一个旋转,该数组的最小值为1。
class Solution {
public int minArray(int[] numbers) {
}
}示例 1:
输入:[3,4,5,1,2]
输出:1示例 2:
输入:[2,2,2,0,1]
输出:0题解
用二分法,但是和普通二分有些区别。
只要找出被旋转的位置,就相当于找出了最小值。
public class Solution {
public int minArray(int[] numbers) {
int left = 0, right = numbers.length - 1;
int middle = 0;
while (left <= right) {
middle = left + (right - left) / 2;
if (numbers[middle] < numbers[right]) {
//如果numbers[middle]<numbers[right]
//说明被旋转的位置区间在[left,middle]
//注意这个地方不是middle-1,因为middle本身就有可能是最小的值
right = middle;
} else if (numbers[middle] > numbers[right]) {
//如果numbers[middle]<numbers[right]
//说明被旋转的位置区间在[middle+1,right]
left = middle + 1;
} else {
//如果numbers[middle]=numbers[right]
//此时不好判断旋转点在左边还是右边,就可以让right--,再继续
right--;
}
}
return numbers[left];
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:38.3 MB, 在所有 Java 提交中击败了31.42%的用户
12 矩阵中的路径
题目
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
class Solution {
public boolean exist(char[][] board, String word) {
}
}
示例 1:
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED"
输出:true示例 2:
输入:board = [["a","b"],["c","d"]], word = "abcd"
输出:false提示:
1 <= board.length <= 2001 <= board[i].length <= 200board 和 word 仅由大小写英文字母组成
题解
回溯/递归
需要board[i][j]=words[k]的原因:
递归搜索匹配字符串过程中,需要
board[i][j] = '\0'来防止在当前这次递归中 ”走回头路“ 。当匹配字符串不成功时,会回溯返回,此时需要board[i][j] = words[k]来”取消对此单元格的标记”。 在DFS过程中,每个单元格会多次被访问的,board[i][j] = '/'只是要保证在当前匹配方案中不要走回头路,当初始i j变化时,又开始了另一次搜索过程。
public class Solution {
public boolean exist(char[][] board, String word) {
for (int i = 0; i < board.length; i++) {
for (int j = 0; j < board[0].length; j++) {
if (dfs(board, word.toCharArray(), i, j, 0)) return true;
}
}
return false;
}
public boolean dfs(char[][] board, char[] words, int i, int j, int k) {
//先判断i,j是否越界,board[i][j]是否不等于word[k]
if (i < 0 || i >= board.length || j < 0 || j >= board[0].length || board[i][j] != words[k]) {
return false;
}
//如果k=words.length-1,说明已经匹配完成,返回true
if (k == words.length - 1) {
return true;
}
//暂时将board[i][j]赋值为空,来表示已经访问过
board[i][j] = '\0';
//向当前元素的上下左右不同方向开始进行下一层的递归,使用||连接,
//(代表只需找到一条可行路径就直接返回,不再做后续 DFS ),并记录结果至 res
boolean res = dfs(board, words, i - 1, j, k + 1) || dfs(board, words, i + 1, j, k + 1) ||
dfs(board, words, i, j - 1, k + 1) || dfs(board, words, i, j + 1, k + 1);
//将当前位置还原
board[i][j] = words[k];
return res;
}
}执行用时:8 ms, 在所有 Java 提交中击败了19.14%的用户
内存消耗:39.2 MB, 在所有 Java 提交中击败了93.75%的用户
13 机器人的运动范围
题目
地上有一个m行n列的方格,从坐标 [0,0] 到坐标 [m-1,n-1] 。一个机器人从坐标 [0, 0] 的格子开始移动,它每次可以向左、右、上、下移动一格(不能移动到方格外),也不能进入行坐标和列坐标的数位之和大于k的格子。例如,当k为18时,机器人能够进入方格 [35, 37] ,因为3+5+3+7=18。但它不能进入方格 [35, 38],因为3+5+3+8=19。请问该机器人能够到达多少个格子?
class Solution {
public int movingCount(int m, int n, int k) {
}
}示例 1:
输入:m = 2, n = 3, k = 1
输出:3示例 2:
输入:m = 3, n = 1, k = 0
输出:1提示:
1 <= n,m <= 1000 <= k <= 20
回溯/递归
public class Solution {
int m, n, k;
boolean[][] visited;
public int movingCount(int m, int n, int k) {
this.m = m;
this.n = n;
this.k = k;
//访问s
this.visited = new boolean[m][n];
return dfs(0, 0);
}
//回溯函数
public int dfs(int i, int j) {
//如果i、j越界 或 i,j的位数和大于k 或 i,j已经访问过,则返回0;
if (i >= m || j >= n || getSum(i) + getSum(j) > k || visited[i][j]) {
return 0;
}
//当前位置标记为访问过
visited[i][j] = true;
return 1 + dfs(i + 1, j) + dfs(i, j + 1);
}
//计算位数和
public int getSum(int n) {
int sum = 0;
while (n != 0) {
sum += n % 10;
n /= 10;
}
return sum;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:35.2 MB, 在所有 Java 提交中击败了81.27%的用户
14 I 剪绳子
题目
给你一根长度为 n 的绳子,请把绳子剪成整数长度的 m 段(m、n都是整数,n>1并且m>1),每段绳子的长度记为 k[0],k[1]…k[m-1] 。请问 k[0]*k[1]*...*k[m-1] 可能的最大乘积是多少?例如,当绳子的长度是8时,我们把它剪成长度分别为2、3、3的三段,此时得到的最大乘积是18。
class Solution {
public int cuttingRope(int n) {
}
}示例 1:
输入: 2
输出: 1
解释: 2 = 1 + 1, 1 × 1 = 1示例 2:
输入: 10
输出: 36
解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36提示:
2 <= n <= 58
题解
数学推论:
1、将绳子以相等的长度等分成多段,得到的乘积最大
2、尽可能将绳子以长度3等分
public class Solution {
public int cuttingRope(int n) {
if (n <= 3) return n - 1;
int a = n / 3, b = n % 3;
if (b == 0) return (int) Math.pow(3, a);
//余1,拆分出一个3,然后再乘4
if (b == 1) return (int) Math.pow(3, a - 1) * 4;
//余2
return (int) Math.pow(3, a) * 2;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:35.1 MB, 在所有 Java 提交中击败了76.10%的用户
15 二进制中1的个数
题目
编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中数字位数为 ‘1’ 的个数(也被称为 汉明重量).)。
提示:
请注意,在某些语言(如 Java)中,没有无符号整数类型。在这种情况下,输入和输出都将被指定为有符号整数类型,并且不应影响您的实现,因为无论整数是有符号的还是无符号的,其内部的二进制表示形式都是相同的。
在 Java 中,编译器使用 二进制补码 记法来表示有符号整数。因此,在上面的 示例 3 中,输入表示有符号整数 -3。
public class Solution {
// you need to treat n as an unsigned value
public int hammingWeight(int n) {
}
}示例 1:
输入:n = 11 (控制台输入 00000000000000000000000000001011)
输出:3
解释:输入的二进制串 00000000000000000000000000001011 中,共有三位为 '1'。示例 2:
输入:n = 128 (控制台输入 00000000000000000000000010000000)
输出:1
解释:输入的二进制串 00000000000000000000000010000000 中,共有一位为 '1'。示例 3:
输入:n = 4294967293 (控制台输入 11111111111111111111111111111101,部分语言中 n = -3)
输出:31
解释:输入的二进制串 11111111111111111111111111111101 中,共有 31 位为 '1'。提示:
输入必须是长度为 32 的 二进制串 。
题解
逐位判断
若n&1=0,则n二进制最右边一位为0;
若n&1=1,则n二进制最右边一位为1;
每次判断最右一位后,将n右移一位
java中的
>>表示有符号右移,
>>>表示无符号右移,高位补0
public class Solution {
public int hammingWeight(int n) {
int res = 0;
while (n != 0) {
res += n & 1;
n >>>= 1;
}
return res;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:35.4 MB, 在所有 Java 提交中击败了38.60%的用户
n&(n-1)
n&(n-1)的结果是将n的最右边的1变成0
public class Solution {
public int hammingWeight(int n) {
int res = 0;
while (n != 0) {
res++;
n &= (n - 1);
}
return res;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:35.2 MB, 在所有 Java 提交中击败了82.41%的用户
16 数值的整数次方
题目
实现 pow(x, n) ,即计算 x 的 n 次幂函数(即,xn)。不得使用库函数,同时不需要考虑大数问题。
class Solution {
public double myPow(double x, int n) {
}
}示例 1:
输入:x = 2.00000, n = 10
输出:1024.00000示例 2:
输入:x = 2.10000, n = 3
输出:9.26100示例 3:
输入:x = 2.00000, n = -2
输出:0.25000
解释:2-2 = 1/22 = 1/4 = 0.25提示:
-100.0 < x < 100.0-231 <= n <= 231-1-104 <= xn <= 104
题解
快速幂
快速幂的大致思路:

public class Solution {
public double myPow(double x, int n) {
if (x == 0) return 0;
long b = n;
double res = 1;
if (b < 0) {
x = 1 / x;
b = -b;
}
while (b > 0) {
//如果b的最后一位为1,则给res乘上x
if ((b & 1) == 1) {
res *= x;
}
x *= x;
b >>= 1;
}
return res;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:36.5 MB, 在所有 Java 提交中击败了84.57%的用户
18 删除列表的节点
题目
给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。
返回删除后的链表的头节点。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode deleteNode(ListNode head, int val) {
}
}示例 1:
输入: head = [4,5,1,9], val = 5
输出: [4,1,9]
解释: 给定你链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9.示例 2:
输入: head = [4,5,1,9], val = 1
输出: [4,5,9]
解释: 给定你链表中值为 1 的第三个节点,那么在调用了你的函数之后,该链表应变为 4 -> 5 -> 9.说明:
题目保证链表中节点的值互不相同
若使用 C 或 C++ 语言,你不需要 free 或 delete 被删除的节点
题解
双指针
public class Solution {
public ListNode deleteNode(ListNode head, int val) {
//如果要删除的是head,则直接返回head.next
if (head.val == val)
return head.next;
ListNode fast = head.next;
ListNode slow = head;
while (fast != null) {
if (fast.val == val) {
slow.next = fast.next;
break;
}
fast = fast.next;
slow = slow.next;
}
return head;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:37.9 MB, 在所有 Java 提交中击败了37.42%的用户
19 正则表达式匹配
题目
请实现一个函数用来匹配包含’. ‘和’‘的正则表达式。模式中的字符’.’表示任意一个字符,而’‘表示它前面的字符可以出现任意次(含0次)。在本题中,匹配是指字符串的所有字符匹配整个模式。例如,字符串”aaa”与模式”a.a”和”abaca”匹配,但与”aa.a”和”ab*a”均不匹配。
class Solution {
public boolean isMatch(String s, String p) {
}
}示例 1:
输入:
s = "aa"
p = "a"
输出: false
解释: "a" 无法匹配 "aa" 整个字符串。示例 2:
输入:
s = "aa"
p = "a*"
输出: true
解释: 因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。示例 3:
输入:
s = "ab"
p = ".*"
输出: true
解释: ".*" 表示可匹配零个或多个('*')任意字符('.')。示例 4:
输入:
s = "aab"
p = "c*a*b"
输出: true
解释: 因为 '*' 表示零个或多个,这里 'c' 为 0 个, 'a' 被重复一次。因此可以匹配字符串 "aab"。示例 5:
输入:
s = "mississippi"
p = "mis*is*p*."
输出: false
s 可能为空,且只包含从 a-z 的小写字母。
p 可能为空,且只包含从 a-z 的小写字母以及字符 . 和 *,无连续的 '*'。题解
动态规划
定义动态规划矩阵 dp , dp[i][j] 表示字符串 s 的前 i 个字符和字符串 p 的前 j 个字符能否匹配
dp[0][0]表示空串
状态转移方程推导:
- 当
p[j-1]为字母时
public class Solution {
public boolean validateStackSequences(int[] pushed, int[] popped) {
Stack<Integer> stack = new Stack<>();
int index = 0;
for (int num : pushed) {
//将pushed中的num压入stack
stack.push(num);
//如果stack不为空并且stack顶的元素等于popped[index],
//则弹出栈顶并让index++;
while (!stack.isEmpty() && stack.peek() == popped[index]) {
stack.pop();
index++;
}
}
//如果最后stack为空,说明true
return stack.isEmpty();
}
}执行用时:2 ms, 在所有 Java 提交中击败了88.16%的用户
内存消耗:38 MB, 在所有 Java 提交中击败了63.24%的用户
参考:面试题31. 栈的压入、弹出序列(模拟,清晰图解) – 栈的压入、弹出序列 – 力扣(LeetCode) (leetcode-cn.com)
20 表示数值的字符串
题目
请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。
数值(按顺序)可以分成以下几个部分:
- 若干空格
- 一个 小数 或者 整数
- (可选)一个 ‘e’ 或 ‘E’ ,后面跟着一个 整数
- 若干空格
小数(按顺序)可以分成以下几个部分:
- (可选)一个符号字符(’+’ 或 ‘-‘)
- 下述格式之一:
- 至少一位数字,后面跟着一个点 ‘.’
- 至少一位数字,后面跟着一个点 ‘.’ ,后面再跟着至少一位数字
- 一个点 ‘.’ ,后面跟着至少一位数字
整数(按顺序)可以分成以下几个部分:
- (可选)一个符号字符(’+’ 或 ‘-‘)
- 至少一位数字
部分数值列举如下:
- [“+100”, “5e2”, “-123”, “3.1416”, “-1E-16”, “0123”]
部分非数值列举如下:
- [“12e”, “1a3.14”, “1.2.3”, “+-5”, “12e+5.4”]
class Solution {
public boolean isNumber(String s) {
}
}示例 1:
输入:s = "0"
输出:true示例 2:
输入:s = "e"
输出:false示例 3:
输入:s = "."
输出:false示例 4:
输入:s = " .1 "
输出:true提示:
1 <= s.length <= 20s 仅含英文字母(大写和小写),数字(0-9),加号 '+' ,减号 '-' ,空格 ' ' 或者点 '.' 。
题解
归纳各种正确的情况,排除了正确情况之外的就直接return false就好
public class Solution {
public boolean isNumber(String s) {
if (s == null || s.length() == 0) return false;
s = s.trim();
boolean numFlag = false;
boolean dotFlag = false;
boolean eFlag = false;
for (int i = 0; i < s.length(); i++) {
//如果当前为数字,则numFlag标记为true
if (s.charAt(i) >= '0' && s.charAt(i) <= '9') {
numFlag = true;
//如果当前为'.'且没有出现过'.'或'E'、'e',则dotFlag标记为true
} else if (s.charAt(i) == '.' && !dotFlag && !eFlag) {
dotFlag = true;
//如果当前为'e',并且没有出现过'e'同时出现过数字,则eFlag标记为true,numFlag标记为true
//或当前i==0(因为e1000这种也算数字)
} else if ((s.charAt(i) == 'e' || s.charAt(i) == 'E') && !eFlag && numFlag || i==0) {
eFlag = true;
//由于题目要求中e后面必须要有数字,因此如果这一位为1,则暂时把numFlag改成false
numFlag = false;
//如果当前为'+'或'-',则必须是在第一位或者在'e'后面
} else if ((s.charAt(i) == '+' || s.charAt(i) == '-') && (i == 0 || s.charAt(i - 1) == 'e' || s.charAt(i - 1) == 'E')) {
//其他情况都不是数字
} else {
return false;
}
}
//最后返回numFlag
//主要是为了防止E出现在最后一位的情况
return numFlag;
}
}执行用时:2 ms, 在所有 Java 提交中击败了99.11%的用户
内存消耗:38.2 MB, 在所有 Java 提交中击败了78.13%的用户
21 调整数组顺序使奇数位于偶数前面
题目
输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有奇数位于数组的前半部分,所有偶数位于数组的后半部分。
class Solution {
public int[] exchange(int[] nums) {
}
}示例:
输入:nums = [1,2,3,4]
输出:[1,3,2,4]
注:[3,1,2,4] 也是正确的答案之一。提示:
0 <= nums.length <= 500001 <= nums[i] <= 10000
题解
双指针
- 定义头指针 p1 ,尾指针 p2
- p1 一直往右移,直到它指向的值为偶数
- p2 一直往左移, 直到它指向的值为奇数
- 交换 nums[p1] 和 nums[p2]
- 重复上述操作,直到 p1==p2
public class Solution {
public int[] exchange(int[] nums) {
int p1 = 0, p2 = nums.length - 1;
int temp;
while (p1 < p2) {
//如果p1指向的位置是奇数,则往右移动一格并跳过这次循环
if (nums[p1] % 2 != 0) {
p1++;
continue;
}
//如果p2指向的位置是偶数,则往右移动一格并跳过这次循环
if (nums[p2] % 2 == 0) {
p2--;
continue;
}
//当执行到这一步时,p1指向的是偶数,p2指向的是奇数
//交换p1和p2上的数字
temp = nums[p1];
nums[p1] = nums[p2];
nums[p2] = temp;
//当p1和p2上的位置交换后,
//p1指向的就已经是奇数了,p2指向的也已经是偶数了,
//直接让p1++,p2--跳过dang'qian
p1++;
p2--;
}
return nums;
}
}执行用时:2 ms, 在所有 Java 提交中击败了89.24%的用户
内存消耗:46 MB, 在所有 Java 提交中击败了89.88%的用户
22 链表中倒数第k个节点
题目
输入一个链表,输出该链表中倒数第k个节点。为了符合大多数人的习惯,本题从1开始计数,即链表的尾节点是倒数第1个节点。
例如,一个链表有 6 个节点,从头节点开始,它们的值依次是 1、2、3、4、5、6。这个链表的倒数第 3 个节点是值为 4 的节点。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode getKthFromEnd(ListNode head, int k) {
}
}示例:
给定一个链表: 1->2->3->4->5, 和 k = 2.
返回链表 4->5.题解
双指针
fast先向前移动k个位置
然后fast和slow一起移动,当fast为null时,slow指向的就是倒数第k个节点
public class Solution {
public ListNode getKthFromEnd(ListNode head, int k) {
ListNode fast = head;
ListNode slow = head;
for (int i = 0; i < k; i++) {
fast = fast.next;
}
while (fast != null) {
fast = fast.next;
slow = slow.next;
}
return slow;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:36.1 MB, 在所有 Java 提交中击败了77.89%的用户
24 反转链表
题目
定义一个函数,输入一个链表的头节点,反转该链表并输出反转后链表的头节点。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode reverseList(ListNode head) {
}
}题解
初步思路
使用双指针的方法;
定义一个fast和一个slow指针,fast在前slow在后,每次把fast的next指向slow,再将fast和slow都向前移动;
循环多次后,链表就反转了。
public class Solution {
public ListNode reverseList(ListNode head) {
ListNode fast = head;
ListNode slow = null;
//注意初始状态,slow是null,才能保证反转后最后一个节点的next为null
while (fast != null) {
ListNode temp = fast.next;
//定义一个temp来暂存fast的下一个
fast.next = slow;
slow = fast;
fast = temp;
}
return slow;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:38.2 MB, 在所有 Java 提交中击败了38.51%的用户
25 合并两个排序的链表
题目
输入两个递增排序的链表,合并这两个链表并使新链表中的节点仍然是递增排序的。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) { val = x; }
* }
*/
class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
}
}示例1:
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->4限制:
0 <= 链表长度 <= 1000题解
public class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
//定义dum节点表示新链表的头节点的前一个节点
ListNode dum = new ListNode(0);
ListNode cur = dum;
//l1和l2中有一个为null,则停止
while (l1 != null && l2 != null) {
if (l1.val < l2.val) {
cur.next = l1;
l1 = l1.next;
} else {
cur.next = l2;
l2 = l2.next;
}
cur = cur.next;
}
//讲不为null的直接接在cur的
cur.next = l1 == null ? l2 : l1;
return dum.next;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:38.4 MB, 在所有 Java 提交中击败了79.34%的用户
26 树的子结构
题目
输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构)
B是A的子结构, 即 A中有出现和B相同的结构和节点值。
例如:
给定的树 A:
3
/ \
4 5
/ \
1 2给定的树 B:
4
/
1返回 true,因为 B 与 A 的一个子树拥有相同的结构和节点值。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public boolean isSubStructure(TreeNode A, TreeNode B) {
}
}示例 1:
输入:A = [1,2,3], B = [3,1]
输出:false示例 2:
输入:A = [3,4,5,1,2], B = [4,1]
输出:true题解
思路
要遍历树,很常用的思路就是用递归。
其实在写递归的时候,我们只需要知道这个函数每一步要实现的操作是什么,不需要去纠结具体的递归的过程。
这道题要我们判断B是不是A的子结构,分析一下函数的大概思路:
1、用一个函数遍历A树的节点
2、以A的每个节点为基准,和B进行比较(需要一个辅助函数isSub)
假设A每次遍历到的节点为Na,B每次遍历到的节点为Nb,辅助函数的流程:
1、如果Nb==null,说明B遍历到底了,返回true
2、如果Nb!=null && Na==null || Nb.val!=Na.val,则返回false
3、递归调用return isSub(Na.left,Nb.left) && isSub(Na.right,Nb.right)
public class Solution {
public boolean isSubStructure(TreeNode A, TreeNode B) {
if (B == null || A == null) return false;
//先从根节点判断B是不是A的子结构,如果不是在分别从左右两个子树判断,
//只要有一个为true,就说明B是A的子结构
return isSub(A, B) || isSubStructure(A.left, B) || isSubStructure(A.right, B);
}
public boolean isSub(TreeNode Na, TreeNode Nb) {
//这里如果B为空,说明B已经访问完了,确定是A的子结构
if (Nb == null) return true;
//如果B不为空A为空,或者这两个节点值不同,说明B树不是A的子结构,直接返回false
if (Na == null || Nb.val != Na.val) return false;
//当前节点比较完之后还要继续判断左右子节点
return isSub(Na.left, Nb.left) && isSub(Na.right, Nb.right);
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:39.6 MB, 在所有 Java 提交中击败了98.40%的用户
27 二叉树的镜像
题目
请完成一个函数,输入一个二叉树,该函数输出它的镜像。
例如输入:
4
/ \
2 7
/ \ / \
1 3 6 9镜像输出:
4
/ \
7 2
/ \ / \
9 6 3 1/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public boolean isSubStructure(TreeNode A, TreeNode B) {
}
}示例 1:
输入:root = [4,2,7,1,3,6,9]
输出:[4,7,2,9,6,3,1]题解
1、交换当前节点的左右子节点
2、递归调用
class Solution {
public TreeNode mirrorTree(TreeNode root) {
if (root == null) return null;
TreeNode temp = root.left;
root.left = root.right;
root.right = temp;
if (root.left != null) mirrorTree(root.left);
if (root.right != null) mirrorTree(root.right);
return root;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:35.5 MB, 在所有 Java 提交中击败了95.94%的用户
28 对称的二叉树
题目
请实现一个函数,用来判断一棵二叉树是不是对称的。如果一棵二叉树和它的镜像一样,那么它是对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1
/ \
2 2
/ \ / \
3 4 4 3但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
1
/ \
2 2
\ \
3 3/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public boolean isSubStructure(TreeNode A, TreeNode B) {
}
}示例 1:
输入:root = [4,2,7,1,3,6,9]
输出:[4,7,2,9,6,3,1]题解
创建一个辅助函数,每次递归调用
public class Solution {
public boolean isSymmetric(TreeNode root) {
if (root == null) return true;
return help(root.left, root.right);
}
public boolean help(TreeNode left, TreeNode right) {
//如果左右节点同时为null,就返回true
if (left == null && right == null) return true;
//如果有一个节点节点为null,或者左右
if (left == null || right == null || left.val != right.val) return false;
//将left.left和right.right、left.right和right.left比较
return help(left.left, right.right) && help(left.right, right.left);
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:35.5 MB, 在所有 Java 提交中击败了95.94%的用户
29 顺时针打印矩阵
题目
输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。
class Solution {
public int[] spiralOrder(int[][] matrix) {
}
}示例 1:
输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[1,2,3,6,9,8,7,4,5]示例 2:
输入:matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]
输出:[1,2,3,4,8,12,11,10,9,5,6,7]限制:
0 <= matrix.length <= 1000 <= matrix[i].length <= 100
题解
模拟
定义上下左右四个边界,从外至内循环遍历并缩小边界
public class Solution {
public int[] spiralOrder(int[][] matrix) {
if (matrix.length == 0) return new int[0];
int row = matrix.length, col = matrix[0].length;
int[] res = new int[row * col];
//定义四个边界
int top = 0, left = 0, right = col - 1, under = row - 1;
int x = 0;
while (true) {
//遍历上边
for (int i = left; i <= right; i++) {
res[x++] = matrix[top][i];
}
if (++top > under) break;
//遍历右边
for (int i = top; i <= under; i++) {
res[x++] = matrix[i][right];
}
if (--right < left) break;
//遍历下边
for (int i = right; i >= left; i--) {
res[x++] = matrix[under][i];
}
if (--under < top) break;
//遍历左边
for (int i = under; i >= top; i--) {
res[x++] = matrix[i][left];
}
if (++left > right) break;
}
return res;
}
}执行用时:1 ms, 在所有 Java 提交中击败了97.43%的用户
内存消耗:39.8 MB, 在所有 Java 提交中击败了44.19%的用户
参考:面试题29. 顺时针打印矩阵(模拟、设定边界,清晰图解) – 顺时针打印矩阵 – 力扣(LeetCode) (leetcode-cn.com)
30 包含min的栈
题目
定义栈的数据结构,请在该类型中实现一个能够得到栈的最小元素的 min 函数在该栈中,调用 min、push 及 pop 的时间复杂度都是 O(1)。
class MinStack {
public MinStack() {
}
public void push(int x) {
}
public void pop() {
}
public int top() {
}
public int min() {
}
}题解
这道题的朴素做法很简单,但是题目要求我们调用min的时间复杂度是O(1)所以朴素做法肯定不行。
我们需要采用辅助栈的方法,用空间换取时间。
定义两个栈分别叫stack1和stack2;
stack1用来进行正常的栈操作,stack2则存储实时的最小值。
public class MinStack {
Stack<Integer> stack1;
Stack<Integer> stack2;
public MinStack() {
stack1 = new Stack<>();
stack2 = new Stack<>();
stack2.push(Integer.MAX_VALUE);
}
public void push(int x) {
stack1.push(x);
stack2.push(Math.min(x, stack2.peek()));
//每次stack2push的都是当前stack1中实时的最小值
}
public void pop() {
stack1.pop();
stack2.pop();
}
public int top() {
return stack1.peek();
}
public int min() {
return stack2.peek();
}
}执行用时:17 ms, 在所有 Java 提交中击败了94.11%的用户
内存消耗:40.4 MB, 在所有 Java 提交中击败了19.29%的用户
31 栈的压入,弹出序列
题目
输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如,序列 {1,2,3,4,5} 是某栈的压栈序列,序列 {4,5,3,2,1} 是该压栈序列对应的一个弹出序列,但 {4,3,5,1,2} 就不可能是该压栈序列的弹出序列。
class Solution {
public boolean validateStackSequences(int[] pushed, int[] popped) {
}
}示例 1:
输入:pushed = [1,2,3,4,5], popped = [4,5,3,2,1]
输出:true
解释:我们可以按以下顺序执行:
push(1), push(2), push(3), push(4), pop() -> 4,
push(5), pop() -> 5, pop() -> 3, pop() -> 2, pop() -> 1示例 2:
输入:pushed = [1,2,3,4,5], popped = [4,3,5,1,2]
输出:false
解释:1 不能在 2 之前弹出。提示:
0 <= pushed.length == popped.length <= 10000 <= pushed[i], popped[i] < 1000pushed 是 popped 的排列。
题解
模拟
public class Solution {
public boolean validateStackSequences(int[] pushed, int[] popped) {
Stack<Integer> stack = new Stack<>();
int index = 0;
for (int num : pushed) {
//将pushed中的num压入stack
stack.push(num);
//如果stack不为空并且stack顶的元素等于popped[index],
//则弹出栈顶并让index++;
while (!stack.isEmpty() && stack.peek() == popped[index]) {
stack.pop();
index++;
}
}
//如果最后stack为空,说明true
return stack.isEmpty();
}
}执行用时:2 ms, 在所有 Java 提交中击败了88.16%的用户
内存消耗:38 MB, 在所有 Java 提交中击败了63.24%的用户
参考:面试题31. 栈的压入、弹出序列(模拟,清晰图解) – 栈的压入、弹出序列 – 力扣(LeetCode) (leetcode-cn.com)
32 I 从上到下打印二叉树
题目
从上到下打印出二叉树的每个节点,同一层的节点按照从左到右的顺序打印。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int[] levelOrder(TreeNode root) {
}
}例如:
给定二叉树: [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7返回:
[3,9,20,15,7]题解
这种题都是用BFS(广度优先)
BFS的思路:
1、创建一个list和一个queue
2、只要队列不为空则一直持续BFS循环:
①弹出队首元素并将它的值存入list
②如果这个元素的左(右)子节点不为空,则将其添加入队列
3、最后list中就是二叉树中从上至下的元素值
public class Solution {
public int[] levelOrder(TreeNode root) {
if (root == null) return new int[0];
Queue<TreeNode> queue = new ArrayDeque<>();
List<Integer> list = new ArrayList<>();
queue.add(root);
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
list.add(node.val);
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
int[] res = new int[list.size()];
for (int i = 0; i < list.size(); i++) {
res[i] = list.get(i);
}
return res;
//return list.stream().mapToInt(Integer::valueOf).toArray();
//steam的写法,但是好像比直接遍历耗时更久
}
}执行用时:1 ms, 在所有 Java 提交中击败了99.35%的用户
内存消耗:38.5 MB, 在所有 Java 提交中击败了70.89%的用户
32 II 从上到下打印二叉树
题目
从上到下按层打印二叉树,同一层的节点按从左到右的顺序打印,每一层打印到一行。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
}
}例如:
给定二叉树: [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7返回:
[
[3],
[9,20],
[15,7]
]题解
与32I的传统BFS有所不同,这个题要求的结果是分层的,这就需要我们在BFS中添加一层
public class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> list = new ArrayList<>();
Queue<TreeNode> queue = new ArrayDeque<>();
if (root != null) queue.add(root);
while (!queue.isEmpty()) {
List<Integer> temp = new ArrayList<>();
for (int i = queue.size(); i > 0; i--) {
//关键!
//让i从queue.size()递减,就不需要担心queue的长度会变化了,因为在for中初始化的操作只执行一次
//每次queue.size()就表示这一层的所有元素的个数
TreeNode node = queue.poll();
temp.add(node.val);
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
list.add(temp);
}
return list;
}
}执行用时:1 ms, 在所有 Java 提交中击败了94.07%的用户
内存消耗:38.5 MB, 在所有 Java 提交中击败了67.98%的用户
32 III 从上到下打印二叉树
题目
请实现一个函数按照之字形顺序打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右到左的顺序打印,第三行再按照从左到右的顺序打印,其他行以此类推。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
}
}例如:
给定二叉树: [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7返回:
[
[3],
[20,9],
[15,7]
]题解
其实和32II一样,偶数层翻转一下就可以了。
public class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> list = new ArrayList<>();
Queue<TreeNode> queue = new ArrayDeque<>();
int flag = 1;
if (root != null) queue.add(root);
while (!queue.isEmpty()) {
List<Integer> temp = new ArrayList<>();
for (int i = queue.size(); i > 0; i--) {
//关键!
//让i从queue.size()递减,就不需要担心queue的长度会变化了,因为在for中初始化的操作只执行一次
//每次queue.size()就表示这一层的所有元素的个数
TreeNode node = queue.poll();
temp.add(node.val);
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
if (flag == -1)
Collections.reverse(temp);
flag *= -1;
list.add(temp);
}
return list;
}
}执行用时:1 ms, 在所有 Java 提交中击败了98.60%的用户
内存消耗:38.5 MB, 在所有 Java 提交中击败了73.78%的用户
或者偶数层从list末尾加数字也行。
public class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> list = new ArrayList<>();
Queue<TreeNode> queue = new ArrayDeque<>();
int flag = 1;
if (root != null) queue.add(root);
while (!queue.isEmpty()) {
LinkedList<Integer> temp = new LinkedList<>();
for (int i = queue.size(); i > 0; i--) {
//关键!
//让i从queue.size()递减,就不需要担心queue的长度会变化了,因为在for中初始化的操作只执行一次
//每次queue.size()就表示这一层的所有元素的个数
TreeNode node = queue.poll();
if (flag == -1) temp.addFirst(node.val);
//如果是偶数层就每次添加在前面
else temp.addLast(node.val);
//如果是奇数层就正常添加在后面
if (node.left != null) queue.add(node.left);
if (node.right != null) queue.add(node.right);
}
flag *= -1;
list.add(temp);
}
return list;
}
}执行用时:1 ms, 在所有 Java 提交中击败了98.60%的用户
内存消耗:38.5 MB, 在所有 Java 提交中击败了83.35%的用户
33 二叉搜索树的后续遍历序列
题目
输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历结果。如果是则返回 true,否则返回 false。假设输入的数组的任意两个数字都互不相同。
参考以下这颗二叉搜索树:
5
/ \
2 6
/ \
1 3class Solution {
public boolean verifyPostorder(int[] postorder) {
}
}示例 1:
输入: [1,6,3,2,5]
输出: false示例 2:
输入: [1,3,2,6,5]
输出: true提示:
数组长度 <= 1000
题解
后序遍历: [ 左子树 | 右子树 | 根节点 ]

上图二叉树后续遍历结果:[3,5,4,10,12,9]
后序遍历的最后一个数一定是root,从前向后找到第一个大于root的数(即10);
在10前面的都是root的左子树,在10后面的(不包括root)都是root的右子树。
通过这种方式,就把后续遍历的数组的左子树和右子树分开了。
由于是从左遍历过来的,因此左边的值一定都比root小,还需要确定右边的值都比root大。
最后递归调用左右节点。
public class Solution {
public boolean verifyPostorder(int[] postorder) {
return recur(postorder, 0, postorder.length - 1);
}
public boolean recur(int[] postorder, int left, int right) {
if (left >= right) return true;
int mid = left;
//根节点的值一定在最右边
int root_val = postorder[right];
//找到第一个大于root的下标
while (postorder[mid] < root_val)
mid++;
//判断一下右边的值是否都大于root的值
int temp = mid;
while (temp < right) {
if (postorder[temp++] < root_val) {
return false;
}
}
//递归调用左右节点
return recur(postorder, left, mid - 1) && recur(postorder, mid, right - 1);
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:35.5 MB, 在所有 Java 提交中击败了98.62%的用户
34 二叉树中和为某一值的路径
题目
输入一棵二叉树和一个整数,打印出二叉树中节点值的和为输入整数的所有路径。从树的根节点开始往下一直到叶节点所经过的节点形成一条路径。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode() {}
* TreeNode(int val) { this.val = val; }
* TreeNode(int val, TreeNode left, TreeNode right) {
* this.val = val;
* this.left = left;
* this.right = right;
* }
* }
*/
class Solution {
public List<List<Integer>> pathSum(TreeNode root, int target) {
}
}示例:
给定如下二叉树,以及目标和 target = 22,
5
/ \
4 8
/ / \
11 13 4
/ \ / \
7 2 5 1返回:
[
[5,4,11,2],
[5,8,4,5]
]提示:
节点总数 <= 10000
题解
回溯
- 递推参数当前节点root,当前目标值tar
- 终止条件:root为null时,直接返回
- 递归过程
- 更新path:
root.val加入path - 更新tar:
tar-=root.val - 更新res:如果当前节点是叶节点,并且路径和为target(即tar=0)
- 递归:递归遍历左右节点
- 恢复path:回溯前需要将当前节点从path中删除
public class Solution {
LinkedList<List<Integer>> res = new LinkedList<>();
LinkedList<Integer> path = new LinkedList<>();
public List<List<Integer>> pathSum(TreeNode root, int sum) {
dfs(root, sum);
return res;
}
public void dfs(TreeNode root, int tar) {
if (root == null) return;
path.add(root.val);
//tar
tar -= root.val;
if (tar == 0 && root.left == null && root.right == null)
//不能直接添加path,因为path只是一个引用,当退出这个函数就会被删除
res.add(new LinkedList(path));
dfs(root.left, tar);
dfs(root.right, tar);
path.removeLast();
}
}执行用时:1 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:38.8 MB, 在所有 Java 提交中击败了54.01%的用户
35 复杂链表的复制
题目
请实现 copyRandomList 函数,复制一个复杂链表。在复杂链表中,每个节点除了有一个 next 指针指向下一个节点,还有一个 random 指针指向链表中的任意节点或者 null。
/*
Definition for a Node.
class Node {
int val;
Node next;
Node random;
public Node(int val) {
this.val = val;
this.next = null;
this.random = null;
}
}
*/
class Solution {
public Node copyRandomList(Node head) {
}
}题解
思路(哈希表)
如果要我们复制一个普通链表,这是相对比较简单的,可以设计如下代码:
public ListNode copyList(ListNode head) {
ListNode dum = new ListNode(0);//定义哑节点,避免链表头没有pre节点
ListNode pre = dum;//前驱节点,初始化为dum
while (head != null) {
ListNode cur = new ListNode(head.val);//复制一份节点
pre.next = cur;//前驱节点的next指针指向当前节点
head = head.next;//向后遍历
pre = cur;//保存这个节点,作为下一个节点的前驱节点
}
return dum.next;
}可以分析一下,复制链表主要有两个步骤:1、复制节点;2、使构建出的节点的指针指向下一个节点;
这是两个不相关的过程,我们正常的流程应该是:先复制所有的节点,再从头开始构建指针指向;
而由于每个节点的next都是有顺序的,不会被打乱,因此我们可以把这两个步骤拆分开来放进循环体中。
但这题与复制普通链表的不同点在于,这个链表的每个节点除了next指针外,还有一个random指针;
random指针的指向是不确定的,如果我们把它引入循环不断找下一个random,可能会形成一个闭环。
所以这道题,我们需要把上述两个步骤拆分开:
public class Solution {
public Node copyRandomList(Node head) {
if (head == null) return null;
Map<Node, Node> map = new HashMap<>();
//创建map的原因是为了保留一开始节点按照next遍历的顺序;
Node cur = head;//定义一个cur,用cur来遍历,以便找回原链表的头节点
//第一轮遍历:构建节点并且按照原链表next遍历的顺序存入map
//map本身是无序的,但是只要在get时的key是有序的,那么取出来的value就不会乱
while (cur != null) {
Node node = new Node(cur.val);
map.put(cur, node);
//每当有新节点创建,就在map中存入一个key为原链表节点,value为新链表节点的键值对
cur = cur.next;
}
cur = head;//让cur复位到head,进行下一轮遍历
//第二轮遍历:构建每个节点的next和random指针指向
while (cur != null) {
map.get(cur).next = map.get(cur.next);
map.get(cur).random = map.get(cur.random);
cur = cur.next;
}
return map.get(head);
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:38.1 MB, 在所有 Java 提交中击败了52.05%的用户
优化思路(原地修改)
在刚才的方法中,因为创建了哈希表的原因,导致空间复杂度有些高了。
那么怎么优化呢?
仔细想想刚才哈希表的作用,是为了保持住按照原链表按next遍历的顺序,那一定需要创建哈希表才能做到这样的效果吗?
其实我们还可以通过原地复制的办法做到。
具体思路:
假设原链表为 $node1\rightarrow node2\rightarrow node3\rightarrow \cdots$ (只看next指针顺序)
则我们可以在原地复制每个节点 $node1\rightarrow node1_{new} \rightarrow node2\rightarrow node2_{new} \rightarrow node3\rightarrow node3_{new} \rightarrow \cdots$
此时我们只需要给新节点构建random指针指向,再拆分就行了。
public Node copyRandomList(Node head) {
if (head == null) return null;
//第一步操作:原地复制原链表的每个节点,并按next指针拼接起来
Node cur = head;
while (cur != null) {
Node temp = new Node(cur.val);
temp.next = cur.next;
cur.next = temp;
cur = temp.next;
}
//第二部操作:构建新节点的random指向
cur = head;
while (cur != null) {
if (cur.random != null)
cur.next.random = cur.random.next;
//cur.next.random相当于newNode.random
//由于第一步操作构建时,每一个旧节点的next都是一个一模一样的新节点
//所以新节点的random就等于旧节点的random的next
cur = cur.next.next;
}
//第三步操作:把两个链表拆分开来
cur = head.next;//cur表示新链表
Node pre = head, res = head.next;//pre表示旧链表
while (cur.next != null) {
pre.next = pre.next.next;
cur.next = cur.next.next;
pre = pre.next;
cur = cur.next;
}
pre.next = null;
//由于在构建节点时,旧链表最后一个节点的next指向的是旧链表的最后一个节点,所以需要让它重新指向null
return res;
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:37.8 MB, 在所有 Java 提交中击败了84.64%的用户
36 二叉搜索树与双向链表
题目
数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
class Solution {
public int majorityElement(int[] nums) {
}
}题解
中序遍历
中序遍历二叉树,因为是中序遍历,所以遍历顺序就是双线链表的建立顺序。我们只需要在中序遍历的过程中,修改每个节点的左右指针,将零散的节点连接成双向循环链表。
public class Solution {
Node head, pre;
public Node treeToDoublyList(Node root) {
if (root == null) return null;
dfs(root);
//最后head就是头节点,pre是尾节点
head.left = pre;
pre.right = head;
return head;
}
public void dfs(Node cur) {
if (cur == null) return;
//中序遍历
dfs(cur.left);
//上一步dfs(cur.left)执行完之后,当前的这个cur指向的是二叉树左下角的叶节点
//即最小的那个元素,此时将head定义为这个元素
if (pre == null) head = cur;
else pre.right = cur;
//当前节点的left赋值为pre
cur.left = pre;
//更新pre
pre = cur;
dfs(cur.right);
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:37.8 MB, 在所有 Java 提交中击败了50.55%的用户
37 序列化二叉树
题目
请实现两个函数,分别用来序列化和反序列化二叉树。
你需要设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
提示:输入输出格式与 LeetCode 目前使用的方式一致,详情请参阅LeetCode 序列化二叉树的格式。你并非必须采取这种方式,你也可以采用其他的方法解决这个问题。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
public class Codec {
// Encodes a tree to a single string.
public String serialize(TreeNode root) {
}
// Decodes your encoded data to tree.
public TreeNode deserialize(String data) {
}
}
// Your Codec object will be instantiated and called as such:
// Codec codec = new Codec();
// codec.deserialize(codec.serialize(root));示例:
输入:root = [1,2,3,null,null,4,5]
输出:[1,2,3,null,null,4,5]题解
深度优先(先序遍历)
序列化:
由于需要反序列化,因此为了保证数据的完整性,null节点也要保存
反序列化:
先序遍历的结果 [ 根节点 | 左子树 | 右子树 ]。
而在这个[ 左子树 ]中,也同样存在着[ 根节点 | 左子树 | 右子树 ]的结构。
因此只需要递归遍历序列化的结果。保存的null作为递归的回溯点就可以了。
public class Codec {
public String serialize(TreeNode root) {
return dfs(root, "");
}
//先序遍历
public String dfs(TreeNode root, String str) {
if (root == null) {
str += "null,";
} else {
str += str.valueOf(root.val) + ",";
str = dfs(root.left, str);
str = dfs(root.right, str);
}
return str;
}
public TreeNode deserialize(String data) {
String[] split = data.split(",");
List<String> dataList = new LinkedList<>(Arrays.asList(split));
return f(dataList);
}
public TreeNode f(List<String> dataList) {
//当前如果是None,说明遍历到底了,
//就开始返回
if (dataList.get(0).equals("null")) {
dataList.remove(0);
return null;
}
//构建当前节点
TreeNode root = new TreeNode(Integer.valueOf(dataList.get(0)));
//将当前节点移除
dataList.remove(0);
//先遍历当前节点的左子树
root.left = f(dataList);
//后遍历当前节点的右子树
root.right = f(dataList);
return root;
}
}执行用时:105 ms, 在所有 Java 提交中击败了17.27%的用户
内存消耗:41.4 MB, 在所有 Java 提交中击败了8.98%的用户
广度优先
参考:面试题37. 序列化二叉树(层序遍历 BFS ,清晰图解) – 序列化二叉树 – 力扣(LeetCode) (leetcode-cn.com)
public class Codec {
public String serialize(TreeNode root) {
return bfs(root);
}
public String bfs(TreeNode root) {
if (root == null) return "";
StringBuilder stringBuilder = new StringBuilder();
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
if (node != null) {
stringBuilder.append(node.val + ",");
queue.add(node.left);
queue.add(node.right);
} else {
stringBuilder.append("null,");
}
}
stringBuilder.deleteCharAt(stringBuilder.length() - 1);
return stringBuilder.toString();
}
public TreeNode deserialize(String data) {
if (data.equals("")) return null;
String[] split = data.split(",");
List<String> dataList = new LinkedList<>(Arrays.asList(split));
return f(dataList);
}
public TreeNode f(List<String> dataList) {
TreeNode root = new TreeNode(Integer.valueOf(dataList.get(0)));
Queue<TreeNode> queue = new LinkedList<>();
queue.add(root);
int i = 1;
while (!queue.isEmpty()) {
TreeNode node = queue.poll();
if (!dataList.get(i).equals("null")) {
node.left = new TreeNode(Integer.valueOf(dataList.get(i)));
queue.add(node.left);
}
i++;
if (!dataList.get(i).equals("null")) {
node.right = new TreeNode(Integer.parseInt(dataList.get(i)));
queue.add(node.right);
}
i++;
}
return root;
}
}执行用时:470 ms, 在所有 Java 提交中击败了5.12%的用户
内存消耗:42 MB, 在所有 Java 提交中击败了5.03%的用户
38 字符串的排列
题目
输入一个字符串,打印出该字符串中字符的所有排列。
你可以以任意顺序返回这个字符串数组,但里面不能有重复元素。
class Solution {
public String[] permutation(String s) {
}
}示例:
输入:s = "abc"
输出:["abc","acb","bac","bca","cab","cba"]限制:
1 <= s 的长度 <= 8
题解
回溯+剪枝
参考:剑指 Offer 38. 字符串的排列(回溯法,清晰图解) – 字符串的排列 – 力扣(LeetCode) (leetcode-cn.com)
public class Solution {
List<String> res = new LinkedList<>();
char[] arr;
public String[] permutation(String s) {
arr = s.toCharArray();
f(0);
return res.toArray(new String[0]);
}
public void f(int x) {
if (x == arr.length - 1) {
res.add(String.valueOf(arr));
return;
}
//用来判断重复字符
Set<Character> set = new HashSet<>();
for (int i = x; i < arr.length; i++) {
//重复的剪枝
if (set.contains(arr[i])) continue;
set.add(arr[i]);
//交换相当于固定一个位置
swap(i, x);
//进入下一层递归
f(x + 1);
//当结束一层递归时交换回来
swap(i, x);
}
}
public void swap(int a, int b) {
char tmp = arr[a];
arr[a] = arr[b];
arr[b] = tmp;
}
}执行用时:7 ms, 在所有 Java 提交中击败了95.64%的用户
内存消耗:43.4 MB, 在所有 Java 提交中击败了37.16%的用户
39 数组中出现次数超过一半的数字
题目
数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字(众数)。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
class Solution {
public int majorityElement(int[] nums) {
}
}示例 1:
输入: [1, 2, 3, 2, 2, 2, 5, 4, 2]
输出: 2限制:
1 <= 数组长度 <= 50000
题解
哈希表
public class Solution {
public int majorityElement(int[] nums) {
Map<Integer, Integer> map = new HashMap<>();
for (int num : nums) {
map.put(num, map.getOrDefault(num, 0) + 1);
}
int maxNum = 0;
int res = 0;
for (int num : nums) {
if (map.get(num) > maxNum) {
maxNum = map.get(num);
res = num;
}
}
return res;
}
}执行用时:10 ms, 在所有 Java 提交中击败了28.80%的用户
内存消耗:43.7 MB, 在所有 Java 提交中击败了64.24%的用户
排序
对数组进行排序,数组中间的元素一定是众数
public class Solution {
public int majorityElement(int[] nums) {
Arrays.sort(nums);
return nums[nums.length / 2];
}
}执行用时:2 ms, 在所有 Java 提交中击败了57.84%的用户
内存消耗:44.3 MB, 在所有 Java 提交中击败了37.45%的用户
摩尔投票法
设nums的众数为x,数组长度为n
推论一:若记众数的票数为1,非众数的票数为-1,则所有数字的票数>0
推论二:若数组的前a个数字的票数和=0,则数组剩余(n-a)个数字的票数和一定仍>0,即剩下(n-a)个数字的众数仍然为x
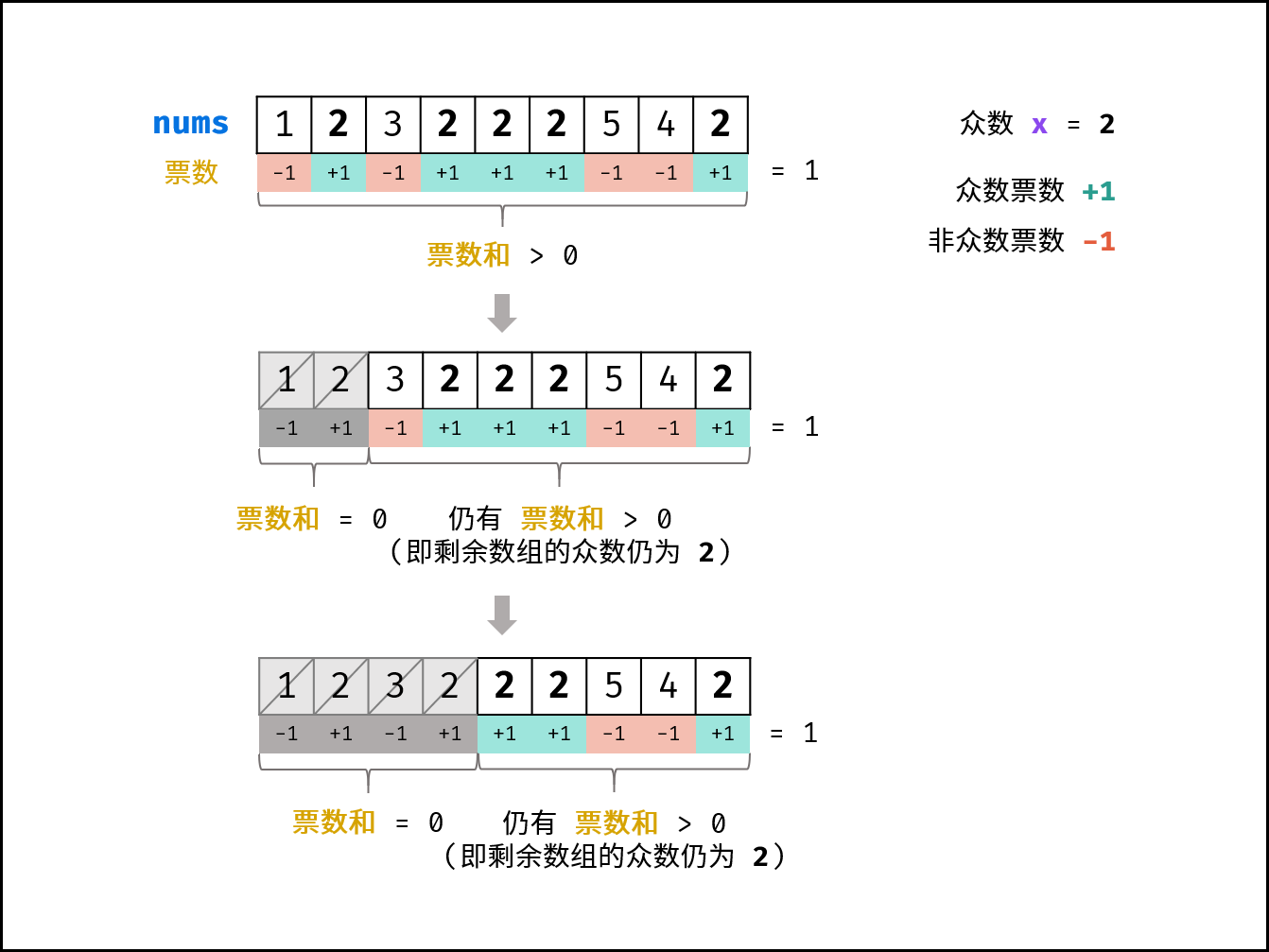
算法大致思路:
1、遍历数组
1、设当前数为众数
2、向后遍历并计算票数和
3、当票数和=0时,缩小剩余数组区间,即重新假设当前数为众数
4、最后一轮假设的数一定是众数
public class Solution {
public int majorityElement(int[] nums) {
//初始化x(众数),votes(当前票数和)
int x = 0, votes = 0;
for (int num : nums) {
//当票数和=0,则假设当前数字是众数
if (votes == 0) x = num;
//加减票数和
votes += num == x ? 1 : -1;
}
return x;
}
}执行用时:1 ms, 在所有 Java 提交中击败了99.95%的用户
内存消耗:41.7 MB, 在所有 Java 提交中击败了87.36%的用户
40 最小的k个数
题目
输入整数数组 arr ,找出其中最小的 k 个数。例如,输入4、5、1、6、2、7、3、8这8个数字,则最小的4个数字是1、2、3、4。
class Solution {
public int maxSubArray(int[] nums) {
}
}示例 1:
输入:arr = [3,2,1], k = 2
输出:[1,2] 或者 [2,1]示例 2:
输入:arr = [0,1,2,1], k = 1
输出:[0]限制:
0 <= k <= arr.length <= 100000 <= arr[i] <= 10000
题解
比较简单,排序一下就行了。
public class Solution {
public int[] getLeastNumbers(int[] arr, int k) {
quickSort(arr, 0, arr.length - 1);
return Arrays.copyOf(arr,k);
}
public void quickSort(int[] nums, int left, int right) {
if (left < right) {
int pivotIndex = getPivotIndex(nums, left, right);
quickSort(nums, left, pivotIndex - 1);
quickSort(nums, pivotIndex + 1, right);
}
}
public int getPivotIndex(int[] nums, int left, int right) {
int pivot = nums[left];
while (left < right) {
while (nums[right] >= pivot && left < right) right--;
nums[left] = nums[right];
while (nums[left] <= pivot && left < right) left++;
nums[right] = nums[left];
}
nums[left] = pivot;
return left;
}
}执行用时:7 ms, 在所有 Java 提交中击败了69.41%的用户
内存消耗:39.7 MB, 在所有 Java 提交中击败了63.39%的用户
41 数据流中的中位数
题目
如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。
例如,
[2,3,4] 的中位数是 3
[2,3] 的中位数是 (2 + 3) / 2 = 2.5
设计一个支持以下两种操作的数据结构:
- void addNum(int num) – 从数据流中添加一个整数到数据结构中。
- double findMedian() – 返回目前所有元素的中位数。
class MedianFinder {
/** initialize your data structure here. */
public MedianFinder() {
}
public void addNum(int num) {
}
public double findMedian() {
}
}
/**
* Your MedianFinder object will be instantiated and called as such:
* MedianFinder obj = new MedianFinder();
* obj.addNum(num);
* double param_2 = obj.findMedian();
*/示例 1:
输入:
["MedianFinder","addNum","addNum","findMedian","addNum","findMedian"]
[[],[1],[2],[],[3],[]]
输出:[null,null,null,1.50000,null,2.00000]示例 2:
输入:
["MedianFinder","addNum","findMedian","addNum","findMedian"]
[[],[2],[],[3],[]]
输出:[null,null,2.00000,null,2.50000]限制:
最多会对 addNum、findMedian 进行 50000 次调用
题解
初步思路
维护一个排序的列表,每次添加数字时二分查找到应该插入的位置
public class MedianFinder {
LinkedList<Integer> list;
public MedianFinder() {
list = new LinkedList<>();
}
public void addNum(int num) {
if(list.isEmpty()){
list.add(num);
return;
}
int left = 0, right = list.size() - 1;
int middle = 0;
while (left <= right) {
middle = left + (right - left) / 2;
if(list.get(middle)<=num){
left=middle+1;
}else {
right=middle-1;
}
}
list.add(left,num);
}
public double findMedian() {
if (list.size() % 2 != 0) {
return list.get(list.size() / 2);
} else {
return ((double) list.get(list.size() / 2) + (double) list.get(list.size() / 2 - 1)) / 2;
}
}
}但是直接超时了。。。毕竟是道困难题,所以还需要寻找更好的方法
大/小顶堆计算中位数
由于中位数只和最中间的两个数字或一个数有关,和其他的数字排序都无关,因此可以用两个堆来实现。
按数组下标从左到右,分成两个堆。
左边是大顶堆A,堆顶朝右,存放这些数中较小的一半,堆顶是这其中最大的数;
右边是小顶堆B,堆顶朝左,存放这些数中较大的一半,堆顶是这其中最小的数。
最终中位数只靠A和B的堆顶元素就可以计算得出。
Java中关于堆结构有一个实现类:PriorityQueue
这本质上是个优先队列,内部用数组的形式维护了一个小顶堆,它不像一般队列满足先进先出原则,而是每次将元素出队时,都是这其中最小的数(可以通过自定义比较器改为最大的)。
Java中PriorityQueue详解 – geekerin – 博客园 (cnblogs.com)
刷算法不知道PriorityQueue?看了这篇文章才知道他有多实用 (baidu.com)
addNum函数:
1、当
A.size()==B.size(),向A中添加一个元素。实现方法:将新元素插入B,再插入A2、当
A.size()!=B.size(),向B中添加一个元素。实现方法:将新元素插入A,再插入B(插入的同时需要将该堆继续维护成原来的大/小顶堆)
为什么向A,B中添加元素的时候不直接插入,而需要先插入另一个堆呢?
因为我们需要时刻保证A中的时较小的那些数,B中是较大的那些数(即A中所有数都要小于B中的),
例如要向A中添加一个元素时,我们不知道这个元素应该是属于A还是B,那么就应该先插入B,然后将B顶的数(即B中最小的数)插入A
findMedian函数
1、当
A.size()==B.size(),中位数等于(A顶+B顶)/22、当
A.size()!=B.size(),中位数等于A顶
代码:
public class MedianFinder {
Queue<Integer> A, B;
public MedianFinder() {
A = new PriorityQueue<>((x, y) -> (y - x));//大顶堆,保存较小的一半
B = new PriorityQueue<>();//小顶堆,保存较大的一半
}
public void addNum(int num) {
if (A.size() == B.size()) {
B.add(num);
A.add(B.poll());
} else {
A.add(num);
B.add(A.poll());
}
}
public double findMedian() {
return A.size() == B.size() ? (A.peek() + B.peek()) / 2.0 : A.peek();
}
}执行用时:68 ms, 在所有 Java 提交中击败了74.95%的用户
内存消耗:49.3 MB, 在所有 Java 提交中击败了87.07%的用户
42 连续子数组的最大和
题目
输入一个整型数组,数组中的一个或连续多个整数组成一个子数组。求所有子数组的和的最大值。
要求时间复杂度为O(n)。
class Solution {
public int maxSubArray(int[] nums) {
}
}示例1:
输入: nums = [-2,1,-3,4,-1,2,1,-5,4]
输出: 6
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。提示:
1 <= arr.length <= 10^5-100 <= arr[i] <= 100
题解
定义动态规划数组dp,dp[i]表示以nums[i]为结尾的连续子数组的最大和,即无论nums[i]是正是负,dp[i]必须包含nums[i];
因为题目要求是连续子数组,如果不包含nums[i],就不能保证递推到dp[i+1]的正确性。
状态转移方程:
若dp[i-1]>0,则dp[i]=dp[i-1]+nums[i]
若dp[i-1]<=0,则dp[i]=nums[i]
public class Solution {
public int maxSubArray(int[] nums) {
if (nums.length == 0) return 0;
int[] dp = new int[nums.length];
dp[0] = nums[0];
for (int i = 1; i < nums.length; i++) {
if (dp[i - 1] > 0){
dp[i] = dp[i - 1] + nums[i];
}
else{
dp[i] = nums[i];
}
}
int max = dp[0];
for (int i : dp) {
if (i > max){
max = i;
}
}
return max;
}
}执行用时:1 ms, 在所有 Java 提交中击败了98.17%的用户
内存消耗:44.8 MB, 在所有 Java 提交中击败了67.68%的用户
45 把数组排成最小的数
题目
输入一个非负整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。
class Solution {
public String minNumber(int[] nums) {
}
}示例 1:
输入: [10,2]
输出: "102"示例 2:
输入: [3,30,34,5,9]
输出: "3033459"提示:
0 < nums.length <= 100
说明:
输出结果可能非常大,所以你需要返回一个字符串而不是整数拼接起来的数字可能会有前导 0,最后结果不需要去掉前导 0
题解
这道题本质是排序,但是排序的规则和正常的规则不太一样;
对于数组nums中的任意两个数x,y:
若x+y>y+x,则x"大于"y
若x+y<y+x,则x"小于"y
套用以上规则,对nums进行排序
使用内置排序
public class Solution {
public String minNumber(int[] nums) {
String[] strs = new String[nums.length];
//把数字都转化成字符串
for (int i = 0; i < nums.length; i++)
strs[i] = String.valueOf(nums[i]);
//使用内置排序,传入两个参数,第一个是string数组,第二个是lambda表达式
//compareto函数是按字典顺序比较两个字符串
Arrays.sort(strs, (x, y) -> (x + y).compareTo(y + x));
StringBuilder res = new StringBuilder();
for (String s : strs)
res.append(s);
return res.toString();
}
}执行用时:5 ms, 在所有 Java 提交中击败了74.27%的用户
内存消耗:37.3 MB, 在所有 Java 提交中击败了99.11%的用户
手动实现快排
快速排序基本思路:
1、选定数组中任意一个数作为pivot
2、将大于pivot的数字放在pivot的右边
3、将小于pivot的数组放在pivot的左边
4、分别对左右子序列重复前三部操作
基本的快排:
public class Test {
public void quickSort(int[] nums, int left, int right) {
if (left < right) {
int pivotIndex = getPivotIndex(nums, left, right);
//在新区间递归
quickSort(nums, left, pivotIndex - 1);
quickSort(nums, pivotIndex + 1, right);
}
}
//对nums进行pivot分区,返回pivot的下标,以便quickSort更新递归区间
public int getPivotIndex(int[] nums, int left, int right) {
//随机选取pivot
int index = new Random().nextInt(right - left + 1) + left;
//交换到left的位置,方便后面填坑法进行调换
swap(nums, left, index);
int pivot = nums[left];
while (left < right) {
//填坑法
//因为nums[left]的值已经暂存在pivot中,因此可以直接覆盖,后面同理
while (nums[right] >= pivot && left < right) right--;
nums[left] = nums[right];
while (nums[left] <= pivot && left < right) left++;
nums[right] = nums[left];
}
nums[left] = pivot;
return left;
}
public void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
}对这个快排模板的交换逻辑修改一下就可以了
public class Solution {
public String minNumber(int[] nums) {
String[] strs = new String[nums.length];
//把数字都转化成字符串
for (int i = 0; i < nums.length; i++)
strs[i] = String.valueOf(nums[i]);
quickSort(strs, 0, strs.length - 1);
StringBuilder stringBuilder = new StringBuilder();
for (String str : strs) {
stringBuilder.append(str);
}
return stringBuilder.toString();
}
public void quickSort(String[] strs, int left, int right) {
if (left < right) {
int pivotIndex = getPivotIndex(strs, left, right);
quickSort(strs, left, pivotIndex - 1);
quickSort(strs, pivotIndex + 1, right);
}
}
public int getPivotIndex(String[] strs, int left, int right) {
int index = new Random().nextInt(right - left + 1) + left;
swap(strs, left, index);
int pivot = Integer.valueOf(strs[left]);
while (left < right) {
while ((strs[right] + pivot).compareTo(pivot + strs[right]) >= 0 && left < right) right--;
strs[left] = strs[right];
while ((pivot + strs[left]).compareTo(strs[left] + pivot) >= 0 && left < right) left++;
strs[right] = strs[left];
}
strs[left] = String.valueOf(pivot);
return left;
}
public void swap(String[] nums, int i, int j) {
String temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
}但是没有进行优化。。。最后执行效果就不看了(太铸币
看一下大佬的优化代码
public class Solution {
public String minNumber(int[] nums) {
String[] strs = new String[nums.length];
for (int i = 0; i < nums.length; i++)
strs[i] = String.valueOf(nums[i]);
quickSort(strs, 0, strs.length - 1);
StringBuilder res = new StringBuilder();
for (String s : strs)
res.append(s);
return res.toString();
}
void quickSort(String[] strs, int l, int r) {
if (l >= r) return;
int i = l, j = r;
String tmp = strs[i];
while (i < j) {
while ((strs[j] + strs[l]).compareTo(strs[l] + strs[j]) >= 0 && i < j) j--;
while ((strs[i] + strs[l]).compareTo(strs[l] + strs[i]) <= 0 && i < j) i++;
tmp = strs[i];
strs[i] = strs[j];
strs[j] = tmp;
}
strs[i] = strs[l];
strs[l] = tmp;
quickSort(strs, l, i - 1);
quickSort(strs, i + 1, r);
}
}执行用时:4 ms, 在所有 Java 提交中击败了98.15%的用户
内存消耗:37.2 MB, 在所有 Java 提交中击败了99.44%的用户
46 把数字翻译成字符串
题目
给定一个数字,我们按照如下规则把它翻译为字符串:0 翻译成 “a” ,1 翻译成 “b”,……,11 翻译成 “l”,……,25 翻译成 “z”。一个数字可能有多个翻译。请编程实现一个函数,用来计算一个数字有多少种不同的翻译方法。
class Solution {
public int translateNum(int num) {
}
}示例 1:
输入: 12258
输出: 5
解释: 12258有5种不同的翻译,分别是"bccfi", "bwfi", "bczi", "mcfi"和"mzi"提示:
0 <= num < 231
题解
回溯
public class Solution {
public int translateNum(int num) {
if (num < 10) {
return 1;
}
if (num % 100 < 26 && num % 100 > 9) {
return translateNum(num / 100) + translateNum(num / 10);
} else {
return translateNum(num / 10);
}
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:35.3 MB, 在所有 Java 提交中击败了34.87%的用户
动态规划
这题和经典的青蛙跳台阶问题类似(青蛙跳台阶,一次可以跳1级,也可以跳2级,问n级台阶多少种跳法)
f(n)=f(n-1)+f(n-2)所以动态规划,只需要知道dp[0]和dp[1],然后递推就好了。
区别在于能不能跳两下需要判断一下。
创建dp数组,dp[i]表示在下标为i处时有多少种翻译方法,用n表示下标为i和i-1构成的两位数;
状态转移方程:
dp[i]=dp[i-2]+dp[i-1] (n>9&&n<26)
dp[i]=dp[i-1] (n<=9&&n>=26)
public class Solution {
public int translateNum(int num) {
char[] chars = String.valueOf(num).toCharArray();
int len = chars.length;
if (len == 1) return 1;
int[] dp = new int[len];
dp[0] = 1;
//dp[1]也需要特判一下
dp[1] = (chars[0] - '0') * 10 + (chars[1] - '0') < 26 ? 2 : 1;
for (int i = 2; i < len; i++) {
//n表示的是i-1和i构成的两位数
int n = (chars[i - 1] - '0') * 10 + (chars[i] - '0');
//n>9&&n<26则说明这个两位数整体可以翻译成字符串
if (n > 9 && n < 26) {
dp[i] = dp[i - 1] + dp[i - 2];
} else {
//否则说明这个两位数整体不能翻译成字符串
dp[i] = dp[i - 1];
}
}
return dp[len - 1];
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:35.3 MB, 在所有 Java 提交中击败了45.25%的用户
动态规划优化(滚动数组)
在上述动态规划中,dp[i]只与dp[i-1]和dp[i-2]有关。
因此只用三个变量,不断更新它们的指,就能得到最终的dp[i]。
public class Solution {
public int translateNum(int num) {
char[] chars = String.valueOf(num).toCharArray();
int len = chars.length;
if (len == 1)
return 1;
int[] dp = new int[3];
dp[0] = 1;
dp[1] = (chars[0] - '0') * 10 + (chars[1] - '0') < 26 ? 2 : 1;
dp[2] = dp[1];
for (int i = 2; i < len; i++) {
int n = (chars[i - 1] - '0') * 10 + (chars[i] - '0');
if (n > 9 && n < 26) {
dp[2] = dp[1] + dp[0];
} else {
dp[2] = dp[1];
}
dp[0] = dp[1];
dp[1] = dp[2];
}
return dp[2];
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:35 MB, 在所有 Java 提交中击败了91.38%的用户
47 礼物的最大价值
题目
在一个 m*n 的棋盘的每一格都放有一个礼物,每个礼物都有一定的价值(价值大于 0)。你可以从棋盘的左上角开始拿格子里的礼物,并每次向右或者向下移动一格、直到到达棋盘的右下角。给定一个棋盘及其上面的礼物的价值,请计算你最多能拿到多少价值的礼物?
class Solution {
public int maxValue(int[][] grid) {
}
}示例 1:
输入:
[
[1,3,1],
[1,5,1],
[4,2,1]
]
输出: 12
解释: 路径 1→3→5→2→1 可以拿到最多价值的礼物提示:
0 < grid.length <= 2000 < grid[0].length <= 200
题解
初步思路
定义动态规划数组dp,dp[i][j]表示在第i行j列的礼物的最大价值
状态转移方程:
dp[i][j]=Math.max(dp[i-1][j],dp[i][j-1])+grid[i][j]
public class Solution {
public int maxValue(int[][] grid) {
int row = grid.length, col = grid[0].length;
int[][] dp = new int[row][col];
dp[0][0] = grid[0][0];
//先对边界初始化
for (int i = 1; i < row; i++) {
dp[i][0] = dp[i - 1][0] + grid[i][0];
}
for (int j = 1; j < col; i++) {
dp[0][j] = dp[0][j - 1] + grid[0][j];
}
for (int i = 1; i < row; i++) {
for (int j = 1; j < col; j++) {
dp[i][j] = Math.max(dp[i - 1][j], dp[i][j - 1]) + grid[i][j];
}
}
return dp[row - 1][col - 1];
}
}执行用时:2 ms, 在所有 Java 提交中击败了98.39%的用户
内存消耗:41.2 MB, 在所有 Java 提交中击败了28.86%的用户
优化
由于dp[i][j]这个位置的值只与dp[i-1][j]和dp[i][j-1]有关;
因此我们可以将原矩阵作为dp矩阵,原地修改grid矩阵
public class Solution {
public int maxValue(int[][] grid) {
int row = grid.length, col = grid[0].length;
for (int i = 1; i < row; i++) {
grid[i][0] += grid[i - 1][0];
}
for (int j = 1; j < col; j++) {
grid[0][j] += grid[0][j - 1];
}
for (int i = 1; i < row; i++) {
for (int j = 1; j < col; j++) {
grid[i][j] += Math.max(grid[i - 1][j], grid[i][j - 1]);
}
}
return grid[row - 1][col - 1];
}
}执行用时:2 ms, 在所有 Java 提交中击败了98.39%的用户
内存消耗:41 MB, 在所有 Java 提交中击败了63.65%的用户
48 最长不含重复字符的子字符串
题目
请从字符串中找出一个最长的不包含重复字符的子字符串,计算该最长子字符串的长度。
class Solution {
public int lengthOfLongestSubstring(String s) {
}
}示例 1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。示例 2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。示例 3:
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。题解
滑动窗口(也算是动态规划吧)
滑动窗口的基本思想:
我们维护一个窗口,
每当当前数字在之前遍历时出现过,就更新 窗口左边界
每遍历一个字符,就计算一次 当前结果
public class Solution {
public int lengthOfLongestSubstring(String s) {
Map<Character, Integer> map = new HashMap<>();
int left = -1;
int result = 0;
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (map.containsKey(c)) {
//防止左边界向左移动
left = Math.max(map.get(c), left);
}
map.put(c, i);
//更新result
result = Math.max(result, i - left);
}
return result;
}
}执行用时:4 ms, 在所有 Java 提交中击败了93.80%的用户
内存消耗:38.2 MB, 在所有 Java 提交中击败了86.78%的用户
50 第一个只出现一次的字符
题目
在字符串 s 中找出第一个只出现一次的字符。如果没有,返回一个单空格。 s 只包含小写字母。
class Solution {
public char firstUniqChar(String s) {
}
}示例:
s = "abaccdeff"
返回 "b"
s = ""
返回 " "题解
HashMap
这个题其实挺简单,也不需要什么花里胡哨的写法,只需要遍历并用HashMap存一下结果就行了。
public class Solution {
public char firstUniqChar(String s) {
Map<Character, Integer> map = new HashMap<>();
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
map.put(c, map.getOrDefault(c, 0) + 1);
}
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
if (map.get(c) == 1) {
return c;
}
}
return ' ';
}
}执行用时:26 ms, 在所有 Java 提交中击败了48.09%的用户
内存消耗:38.6 MB, 在所有 Java 提交中击败了65.39%的用户
LinkedHashMap
也可以用LinkedHashMap,它是一种有顺序的HashMap
public class Solution {
public char firstUniqChar(String s) {
Map<Character, Integer> map = new LinkedHashMap<>();
for (int i = 0; i < s.length(); i++) {
char c = s.charAt(i);
map.put(c, map.getOrDefault(c, 0) + 1);
}
for (char c : map.keySet()) {
if (map.get(c) == 1) {
return c;
}
}
return ' ';
}
}执行用时:26 ms, 在所有 Java 提交中击败了48.09%的用户
内存消耗:38.7 MB, 在所有 Java 提交中击败了61.29%的用户
数组
也可以用纯数组的形式,可以节省一点时间消耗
public class Solution {
public char firstUniqChar(String s) {
//用intl数组可以节省一点空间
int[] arr = new int[26];
char[] chars = s.toCharArray();
for (char ch : chars) {
arr[ch - 'a']++;
}
for (char c : chars) {
if (arr[c - 'a'] == 1) {
return c;
}
}
return ' ';
}
}执行用时:3 ms, 在所有 Java 提交中击败了99.37%的用户
内存消耗:38.7 MB, 在所有 Java 提交中击败了57.02%的用户
52 两个链表的第一个公共节点
题目
输入两个链表,找出它们的第一个公共节点。
如下面的两个链表:

在节点 c1 开始相交。
/**
* Definition for singly-linked list.
* public class ListNode {
* int val;
* ListNode next;
* ListNode(int x) {
* val = x;
* next = null;
* }
* }
*/
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
}
}示例 1:
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Reference of the node with value = 8
输入解释:相交节点的值为 8 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。示例 2:

输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Reference of the node with value = 2
输入解释:相交节点的值为 2 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。示例 3:

输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:null
输入解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
解释:这两个链表不相交,因此返回 null。注意:
如果两个链表没有交点,返回 null.
在返回结果后,两个链表仍须保持原有的结构。
可假定整个链表结构中没有循环。
程序尽量满足 O(n) 时间复杂度,且仅用 O(1) 内存。题解
双指针
定义两个指针p1和p2
p1先遍历headA,如果遍历到尾部,再从headB开始遍历;
p2先遍历headB,如果遍历到尾部,再从headA开始遍历;
当p1和p2相等时,返回p1.
为什么要这样操作呢?
假设headA链表节点数量为a个,headB链表节点数量为b个,两个链表的公共节点数量为c个。设公共节点为node,则在headA到node之间,共有a-c个节点,在headB到node之间,共有b-c个节点。
p1先遍历headA,再从headB开始遍历,当到达node位置时,共走的步数为
a+b-cp2先遍历headB,再从headA开始遍历,当到达node位置时,共走的步数为
b+a-c此时p1和p2走的步数相同,必定重合,重合的位置就是第一个公共节点,因此返回p1即可;
同时,若p1和p2没有公共节点,则p1和p2重合的情况就是p1和p2都指向两个链表的尾部,即null。
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
ListNode p1 = headA;
ListNode p2 = headB;
while (p1 != p2) {
p1 = p1 == null ? headB : p1.next;
p2 = p2 == null ? headA : p2.next;
}
return p1;
}
}执行用时:1 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:41.1 MB, 在所有 Java 提交中击败了74.72%的用户
53 I 在排序数组中查找数字
题目
统计一个数字在排序数组中出现的次数。
class Solution {
public int search(int[] nums, int target) {
}
}示例1:
输入: nums = [5,7,7,8,8,10], target = 8
输出: 2示例2:
输入: nums = [5,7,7,8,8,10], target = 6
输出: 0题解
简单遍历
没什么好说的,遍历,每次++就行了
public class Solution {
public int search(int[] nums, int target) {
int n = 0;
for (int num : nums) {
if (num == target)
n++;
}
return n;
}
}执行用时:1 ms, 在所有 Java 提交中击败了26.78%的用户
内存消耗:41.4 MB, 在所有 Java 提交中击败了28.61%的用户
时间O(n)
空间O(1)
二分查找
直接简单遍历的话,时间复杂度有些高;
关键在于如何找到这个数字在数组中出现的下标和结束的下标,所以这题实质上是一个二分查找
public class Solution {
public int search(int[] nums, int target) {
//找出target的右边界和target-1的右边界
return finder(nums, target) - finder(nums, target - 1);
}
//finder函数实际上找的是右边界
public int finder(int[] nums, int target) {
int left = 0, right = nums.length - 1;
int middle = 0;
while (left <= right) {
middle = left + (right - left) / 2;
//由于我们要找的是右边界,所以等于的情况也需要把区间变成[middle+1,right]
if (nums[middle] <= target) {
left = middle + 1;
} else {
right = middle - 1;
}
}
//当while循环结束时,left=right+1,所以left才是右边的边界
return left;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:41.4 MB, 在所有 Java 提交中击败了41.21%的用户
时间O(logn)
空间O(1)
二分查找的细节推荐博客:二分查找的细节总结 – 鱼跃此时海 (overme.cn)
53 II 0~n-1中缺失的数字
题目
一个长度为n-1的递增排序数组中的所有数字都是唯一的,并且每个数字都在范围0~n-1之内。在范围0~n-1内的n个数字中有且只有一个数字不在该数组中,请找出这个数字。
class Solution {
public int missingNumber(int[] nums) {
}
}示例1:
输入: [0,1,3]
输出: 2示例2:
输入: [0,1,2,3,4,5,6,7,9]
输出: 8题解
二分查找
有了53 I的经验后,这题直接采用二分查找的方法来做。
由于该数组是从0递增的,如果没有缺少,那么数组的值与对应下标都是相等的;
现在少了一个数字i,那么从下标i开始,到数组末尾的这些数都比下标大1;
所以二分法查找,只需要查找出这个边界下标就可以了;
public class Solution {
public int missingNumber(int[] nums) {
return finder(nums);
}
public int finder(int[] nums) {
int left = 0, right = nums.length - 1;
int middle = 0;
while (left <= right) {
middle = left + (right - left) / 2;
//如果nums[middle]与midlle相等,就说明需要往右边找
if (nums[middle] == middle)
left = middle + 1;
//如果不相等,就往左边找
else
right = middle - 1;
}
//关键:要的是右边界
return left;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:38.8 MB, 在所有 Java 提交中击败了73.56%的用户
时间O(logn)
空间O(1)
54 二叉搜索树的第k大节点
题目
给定一棵二叉搜索树,请找出其中第k大的节点。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int kthLargest(TreeNode root, int k) {
}
}示例 1:
输入: root = [3,1,4,null,2], k = 1
3
/ \
1 4
\
2
输出: 4示例 2:
输入: root = [5,3,6,2,4,null,null,1], k = 3
5
/ \
3 6
/ \
2 4
/
1
输出: 4限制:
1 ≤ k ≤ 二叉搜索树元素个数
题解
中序遍历
public class Solution {
List<Integer> res = new ArrayList<>();
public int kthLargest(TreeNode root, int k) {
if (root == null)
return 0;
dfs(root);
return res.get(res.size() - k);
}
public void dfs(TreeNode root) {
if (root == null)
return;
dfs(root.left);
res.add(root.val);
dfs(root.right);
}
}执行用时:1 ms, 在所有 Java 提交中击败了35.01%的用户
内存消耗:38.6 MB, 在所有 Java 提交中击败了24.77%的用户
反向中序遍历
二叉搜索树的中序遍历为递增序列,则与中序遍历相反的遍历方式就是递减序列
可以剩下List的空间和时间消耗
public class Solution {
int k, res;
public int kthLargest(TreeNode root, int k) {
this.k = k;
dfs(root);
return res;
}
public void dfs(TreeNode root) {
if (root == null)
return;
dfs(root.right);
//用k计数
if (--k == 0) res = root.val;
dfs(root.left);
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:38.3 MB, 在所有 Java 提交中击败了45.67%的用户
55 I 二叉树的深度
题目
输入一棵二叉树的根节点,求该树的深度。从根节点到叶节点依次经过的节点(含根、叶节点)形成树的一条路径,最长路径的长度为树的深度。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public int maxDepth(TreeNode root) {
}
}例如:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7返回它的最大深度 3 。
提示:
节点总数 <= 10000
题解
DFS
每一层的最大深度为左右子节点的最大深度中较大的那个+1
public class Solution {
public int maxDepth(TreeNode root) {
if (root == null) return 0;
return Math.max(maxDepth(root.left), maxDepth(root.right)) + 1;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:38.1 MB, 在所有 Java 提交中击败了84.54%的用户
BFS
每遍历完一层给res++
public class Solution {
public int maxDepth(TreeNode root) {
if (root == null) return 0;
Queue<TreeNode> queue = new LinkedList<>();
Queue<TreeNode> temp;
int res = 0;
queue.add(root);
while (!queue.isEmpty()) {
temp = new LinkedList<>();
for (TreeNode node : queue) {
if (node.left != null) temp.add(node.left);
if (node.right != null) temp.add(node.right);
}
queue = temp;
res++;
}
return res;
}
}执行用时:2 ms, 在所有 Java 提交中击败了8.33%的用户
内存消耗:38.1 MB, 在所有 Java 提交中击败了88.87%的用户
后续遍历
从底至顶计算深度
public class Solution {
public int maxDepth(TreeNode node) {
if (node == null) return 0;
int left = maxDepth(node.left);
int right = maxDepth(node.right);
return Math.max(left, right) + 1;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:38.3 MB, 在所有 Java 提交中击败了59.27%的用户
55 II 平衡二叉树
题目
输入一棵二叉树的根节点,判断该树是不是平衡二叉树。如果某二叉树中任意节点的左右子树的深度相差不超过1,那么它就是一棵平衡二叉树。
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public boolean isBalanced(TreeNode root) {
}
}示例 1:
给定二叉树 [3,9,20,null,null,15,7]
3
/ \
9 20
/ \
15 7返回 true 。
示例 2:
给定二叉树 [1,2,2,3,3,null,null,4,4]
1
/ \
2 2
/ \
3 3
/ \
4 4返回 false 。
限制:
0 <= 树的结点个数 <= 10000
题解
先序遍历 + 判断深度
public class Solution {
public boolean isBalanced(TreeNode root) {
if (root == null) return true;
return Math.abs(depth(root.left) - depth(root.right)) <= 1 && isBalanced(root.left) && isBalanced(root.right);
}
public int depth(TreeNode node) {
if (node == null) return 0;
return Math.max(depth(node.left), depth(node.right)) + 1;
}
}执行用时:1 ms, 在所有 Java 提交中击败了83.59%的用户
内存消耗:38.5 MB, 在所有 Java 提交中击败了41.70%的用户
后续遍历+剪枝
对二叉树做后续遍历,从底至顶返回子树的深度,若判定字数不是平衡树则进行剪枝,即直接返回。
后续遍历的特点是从底至顶,由于其是从底至顶,因此在遇到不符合的情况时,可以方便剪枝,提高效率
public class Solution {
public boolean isBalanced(TreeNode root) {
return recur(root) != -1;
}
public int recur(TreeNode node) {
//当node==null,说明越过根节点,返回高度为0
if (node == null) return 0;
//计算左子树深度
int left = recur(node.left);
if (left == -1) return -1;
//计算右子树深度
int right = recur(node.right);
if (right == -1) return -1;
return Math.abs(left - right) <= 1 ? Math.max(left, right) + 1 : -1;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:38.4 MB, 在所有 Java 提交中击败了56.75%的用户
56 I 数组中数字出现的次数
题目
一个整型数组 nums 里除两个数字之外,其他数字都出现了两次。请写程序找出这两个只出现一次的数字。要求时间复杂度是O(n),空间复杂度是O(1)。
class Solution {
public int[] singleNumbers(int[] nums) {
}
}示例 1:
输入:nums = [4,1,4,6]
输出:[1,6] 或 [6,1]示例 2:
输入:nums = [1,2,10,4,1,4,3,3]
输出:[2,10] 或 [10,2]限制:
2 <= nums.length <= 10000
题解
题目要求时间复杂度O(n),空间复杂度O(1),因此排除暴力和哈希
若题目改为,在一个整型数组
nums中除了一个数字x外,其他数字出现了两次,找出x
异或运算:异或运算有个重要的性质,两个相同数字异或为 0
public int[] singleNumber(int[] nums) {
int x = 0;
for(int num : nums) // 1. 遍历 nums 执行异或运算
x ^= num;
return x; // 2. 返回出现一次的数字 x
}这题的难点在于有两个只出现一次的数字,因此无法直接通过上面的异或运算得到这两个数字。
可以将nums拆分成分别带有两个未知数x和y的数组。
拆分的关键在于两个数组必须分别包含x和y,而数组中其他的元素只要保证两两不分开就行。
算法思路:
1、先对所有数字进行一次异或,得到的结果就是x和y的异或值
2、根据异或运算定义,若整数x^y的某二进制位为1.则x和y的这个二进制位一定不同。可以通过这个特性将nums划分为两个数组
3、每个组内进行异或操作,得到两个数字
public class Solution {
public int[] singleNumbers(int[] nums) {
int result = 0;
for (int num : nums) {
result ^= num;
}
//初始化辅助变量div=1,通过与运算从右向左循环判断
//直到获取到x^y的第首位1
int div = 1;
while ((result & div) == 0)
div <<= 1;
int x = 0, y = 0;
for (int num : nums) {
//若num&div!=则与x一组
if ((num & div) != 0) {
x ^= num;
//若num&div==0则与y一组
} else {
y ^= num;
}
}
return new int[]{x, y};
}
}执行用时:1 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:40.1 MB, 在所有 Java 提交中击败了41.50%的用户
56 II 数组中数字出现的次数
题目
输入一个递增排序的数组和一个数字s,在数组中查找两个数,使得它们的和正好是s。如果有多对数字的和等于s,则输出任意一对即可。
class Solution {
public int[] twoSum(int[] nums, int target) {
}
}示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[2,7] 或者 [7,2]示例 2:
输入:nums = [10,26,30,31,47,60], target = 40
输出:[10,30] 或者 [30,10]限制:
1 <= nums.length <= 10^51 <= nums[i] <= 10^6
题解
先看一下我自己一开始的写法,本来想创建数组用空间换时间的,结果时间空间都是铸币(
public class Solution {
public int[] twoSum(int[] nums, int target) {
int[] map = new int[Math.max(nums[nums.length - 1]+1,target)];
for (int num : nums) {
map[num]++;
}
for (int num : nums) {
if (map[target - num] != 0) {
return new int[]{num, target - num};
}
}
return null;
}
}执行用时:5 ms, 在所有 Java 提交中击败了23.31%的用户
内存消耗:59.2 MB, 在所有 Java 提交中击败了5.02%的用户
双指针
这题有个关键条件是排序数组,一开始没看见
定义两个指针,p1指向数组头,p2指向数组尾
- 计算
s=nums[p1]+nums[p2] - 如果
s>target,则p2-- - 如果
s<target,则p1++ - 如果
s=target,则返回数组[nums[p1],nums[p2]]
public class Solution {
public int[] twoSum(int[] nums, int target) {
int p1 = 0, p2 = nums.length - 1;
while (p1 < p2) {
if (nums[p1] + nums[p2] > target) {
p2--;
} else if (nums[p1] + nums[p2] < target) {
p1++;
} else {
return new int[]{nums[p1], nums[p2]};
}
}
return null;
}
}执行用时:2 ms, 在所有 Java 提交中击败了86.49%的用户
内存消耗:55.1 MB, 在所有 Java 提交中击败了80.69%的用户
57 I 和为s的两个数字
题目
输入一个递增排序的数组和一个数字s,在数组中查找两个数,使得它们的和正好是s。如果有多对数字的和等于s,则输出任意一对即可。
class Solution {
public int[] twoSum(int[] nums, int target) {
}
}示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[2,7] 或者 [7,2]示例 2:
输入:nums = [10,26,30,31,47,60], target = 40
输出:[10,30] 或者 [30,10]限制:
1 <= nums.length <= 10^51 <= nums[i] <= 10^6
题解
先看一下我自己一开始的写法,本来想创建数组用空间换时间的,结果时间空间都是铸币(
public class Solution {
public int[] twoSum(int[] nums, int target) {
int[] map = new int[Math.max(nums[nums.length - 1]+1,target)];
for (int num : nums) {
map[num]++;
}
for (int num : nums) {
if (map[target - num] != 0) {
return new int[]{num, target - num};
}
}
return null;
}
}执行用时:5 ms, 在所有 Java 提交中击败了23.31%的用户
内存消耗:59.2 MB, 在所有 Java 提交中击败了5.02%的用户
双指针
这题有个关键条件是排序数组,一开始没看见
定义两个指针,p1指向数组头,p2指向数组尾
- 计算
s=nums[p1]+nums[p2] - 如果
s>target,则p2-- - 如果
s<target,则p1++ - 如果
s=target,则返回数组[nums[p1],nums[p2]]
public class Solution {
public int[] twoSum(int[] nums, int target) {
int p1 = 0, p2 = nums.length - 1;
while (p1 < p2) {
if (nums[p1] + nums[p2] > target) {
p2--;
} else if (nums[p1] + nums[p2] < target) {
p1++;
} else {
return new int[]{nums[p1], nums[p2]};
}
}
return null;
}
}执行用时:2 ms, 在所有 Java 提交中击败了86.49%的用户
内存消耗:55.1 MB, 在所有 Java 提交中击败了80.69%的用户
57 II 和为s的连续正数序列
题目
输入一个正整数 target ,输出所有和为 target 的连续正整数序列(至少含有两个数)。
序列内的数字由小到大排列,不同序列按照首个数字从小到大排列。
class Solution {
public int[][] findContinuousSequence(int target) {
}
}示例 1:
输入:target = 9
输出:[[2,3,4],[4,5]]示例 2:
输入:target = 15
输出:[[1,2,3,4,5],[4,5,6],[7,8]]限制:
1 <= target <= 10^5
题解
滑动窗口
左闭右闭(其实感觉左闭右开应该更符合代码习惯)
public class Solution {
public int[][] findContinuousSequence(int target) {
int left = 1, right = 1;
int sum = 1;
List<int[]> res = new ArrayList<>();
while (left <= target / 2) {
if (sum < target) {
right++;
sum += right;
}
if (sum > target) {
sum -= left;
left++;
}
if (sum == target) {
int[] arr = new int[right - left + 1];
for (int i = left; i <= right; i++) {
arr[i - left] = i;
}
res.add(arr);
sum -= left;
left++;
}
}
return res.toArray(new int[res.size()][]);
}
}执行用时:2 ms, 在所有 Java 提交中击败了97.53%的用户
内存消耗:36.3 MB, 在所有 Java 提交中击败了77.89%的用户
参考:什么是滑动窗口,以及如何用滑动窗口解这道题(C++/Java/Python) – 和为s的连续正数序列 – 力扣(LeetCode) (leetcode-cn.com)
58 I 翻转单词顺序
题目
输入一个英文句子,翻转句子中单词的顺序,但单词内字符的顺序不变。为简单起见,标点符号和普通字母一样处理。例如输入字符串”I am a student. “,则输出”student. a am I”。
class Solution {
public String reverseWords(String s) {
}
}示例 1:
输入: "the sky is blue"
输出: "blue is sky the"示例 2:
输入: " hello world! "
输出: "world! hello"
解释: 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。示例 3:
输入: "a good example"
输出: "example good a"
解释: 如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。说明:
无空格字符构成一个单词。
输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
题解
分隔+倒序
- 用String.trim()删除首尾空格
- 分割字符串 以空格为分割符完成字符串分割后,若两单词间有 x > 1 个空格,则在单词列表 strs 中,此两单词间会多出 x – 1 个 “空单词” (即 “” )。解决方法:倒序遍历单词列表,并将单词逐个添加至 StringBuilder ,遇到空单词时跳过。
- 倒叙遍历,拼接至StringBuilder
- 转化为字符串并返回
由于这种方法用到了几个内置api,所以面试不建议用
public class Solution {
public String reverseWords(String s) {
String[] strs = s.trim().split(" ");
StringBuilder stringBuilder = new StringBuilder();
for (int i = strs.length - 1; i >= 0; i--) {
if (strs[i].equals("")) continue;
stringBuilder.append(strs[i] + " ");
}
return stringBuilder.toString().trim();//q
}
}执行用时:2 ms, 在所有 Java 提交中击败了85.37%的用户
内存消耗:37.9 MB, 在所有 Java 提交中击败了94.89%的用户
双指针
倒序遍历字符串 s ,记录单词左右索引边界 p1 , p2 ;
每确定一个单词的边界,则将其添加至 StringBuilder ;
最终,返回 stringBuilder.toString() 即可。
public class Solution {
public String reverseWords(String s) {
s = s.trim();
int p1 = s.length() - 1, p2 = s.length() - 1;
StringBuilder stringBuilder = new StringBuilder();
while (p1 >= 0) {
while (p1 >= 0 && s.charAt(p1) != ' ') p1--; //找到空格
stringBuilder.append(s.substring(p1 + 1, p2 + 1) + " "); //拼接单词
while (p1 >= 0 && s.charAt(p1) == ' ') p1--; //跳过空格
p2 = p1; //p2指向单词末尾
}
return stringBuilder.toString().trim();
}
}执行用时:3 ms, 在所有 Java 提交中击败了61.65%的用户
内存消耗:37.8 MB, 在所有 Java 提交中击败了98.33%的用户
58 II 左旋转字符串
题目
字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串”abcdefg”和数字2,该函数将返回左旋转两位得到的结果”cdefgab”。
class Solution {
public String reverseLeftWords(String s, int n) {
}
}题解
这题太简单,方法也很多,主要是按照要求选取不同方法就行。
方法一:利用substring方法
把字符串分割成两部分:前n个和剩下的
然后重新拼接
public class Solution {
public String reverseLeftWords(String s, int n) {
String s1 = s.substring(0, n);
String s2 = s.substring(n, s.length());
return s2 + s1;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:37.8 MB, 在所有 Java 提交中击败了97.00%的用户
方法二:用StringBuilder遍历拼接
public class Solution {
public String reverseLeftWords(String s, int n) {
StringBuilder stringBuilder = new StringBuilder();
for (int i = n; i < s.length(); i++) {
stringBuilder.append(s.charAt(i));
}
for (int i = 0; i < n; i++) {
stringBuilder.append(s.charAt(i));
}
return stringBuilder.toString();
}
}执行用时:4 ms, 在所有 Java 提交中击败了34.32%的用户
内存消耗:38.4 MB, 在所有 Java 提交中击败了17.93%的用户
59 I 滑动窗口的最大值
题目
给定一个数组 nums 和滑动窗口的大小 k,请找出所有滑动窗口里的最大值。
class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
}
}示例:
输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3
输出: [3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7提示:
你可以假设 k 总是有效的,在输入数组不为空的情况下,1 ≤ k ≤ 输入数组的大小。
题解
暴力
每次滑动窗口更新就遍历一遍滑动窗口里面的数字,找到最大的那个。
public class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
int length = nums.length;
if (length == 0 || k == 0) return new int[]{};
int[] res = new int[length - k + 1];
for (int i = 0; i < length - k + 1; i++) {
int max = Integer.MIN_VALUE;
for (int j = i; j < k + i; j++) {
max = nums[j] > max ? nums[j] : max;
}
res[i] = max;
}
return res;
}
}执行用时:27 ms, 在所有 Java 提交中击败了18.53%的用户
内存消耗:46.4 MB, 在所有 Java 提交中击败了76.30%的用户
大根堆(优先队列)
对优先队列做任何操作后,队首的元素始终能保持时最大的。
先把前k个数字加入优先队列。
当滑动窗口向右移动时,添加进一个数字,此时队首的元素就是最大的。
但是不能保证这个队首的最大的元素在滑动窗口的范围内,
因此需要判断一下,如果队首的元素不在滑动窗口范围内,就出队,知道满足为止。
public class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
if (nums.length == 0 || k == 0) return new int[0];
//优先队列中存储二元数组(num,index)
//index表示num的下标,用于判断当前优先队列中的最大值在不在这个滑动窗口内
PriorityQueue<int[]> pq = new PriorityQueue<int[]>(new Comparator<int[]>() {
public int compare(int[] pair1, int[] pair2) {
//如果;num1!=num2,返回num2-num1
//否则返回index2-index1
return pair1[0] != pair2[0] ? pair2[0] - pair1[0] : pair2[1] - pair1[1];
}
});
int[] res = new int[nums.length - k + 1];
for (int i = 0; i < k; i++) {
pq.add(new int[]{nums[i], i});
}
res[0] = pq.peek()[0];
for (int i = k; i < nums.length; i++) {
//pq添加进一个元素,表示滑动窗口右边界向右移动一格
pq.add(new int[]{nums[i], i});
//此时逻辑上左边界也向右移动一格
//则左边界为i-k+1,如果pq顶的元素在这个边界之外,则出队
while (pq.peek()[1] <= i - k) {
pq.poll();
}
res[i - k + 1] = pq.peek()[0];
}
return res;
}
}执行用时:11 ms, 在所有 Java 提交中击败了83.53%的用户
内存消耗:47.1 MB, 在所有 Java 提交中击败了54.73%的用户
单调队列
参考:动画演示 单调队列 剑指 Offer 59 – I. 滑动窗口的最大值 – 滑动窗口的最大值 – 力扣(LeetCode) (leetcode-cn.com)
public class Solution {
public int[] maxSlidingWindow(int[] nums, int k) {
if (nums.length == 0 || k == 0) return new int[0];
// 窗口个数
int[] res = new int[nums.length - k + 1];
LinkedList<Integer> queue = new LinkedList<>();
// 遍历数组中元素,right表示滑动窗口右边界
for (int right = 0; right < nums.length; right++) {
// 如果队列不为空且当前考察元素大于等于队尾元素,则将队尾元素移除。
// 直到,队列为空或当前考察元素小于新的队尾元素
while (!queue.isEmpty() && nums[right] >= nums[queue.peekLast()]) {
queue.removeLast();
}
// 存储元素下标
queue.addLast(right);
// 计算窗口左侧边界
int left = right - k + 1;
// 当队首元素的下标小于滑动窗口左侧边界left时
// 表示队首元素已经不再滑动窗口内,因此将其从队首移除
if (queue.peekFirst() < left) {
queue.removeFirst();
}
// 由于数组下标从0开始,因此当窗口右边界right+1大于等于窗口大小k时
// 意味着窗口形成。此时,队首元素就是该窗口内的最大值
if (right + 1 >= k) {
res[left] = nums[queue.peekFirst()];
}
}
return res;
}
}执行用时:10 ms, 在所有 Java 提交中击败了90.09%的用户
内存消耗:46.4 MB, 在所有 Java 提交中击败了75.13%的用户
59 II 队列的最大值
题目
请定义一个队列并实现函数 max_value 得到队列里的最大值,要求函数max_value、push_back 和 pop_front 的均摊时间复杂度都是O(1)。
若队列为空,pop_front 和 max_value 需要返回 -1
class MaxQueue {
public MaxQueue() {
}
public int max_value() {
}
public void push_back(int value) {
}
public int pop_front() {
}
}
/**
* Your MaxQueue object will be instantiated and called as such:
* MaxQueue obj = new MaxQueue();
* int param_1 = obj.max_value();
* obj.push_back(value);
* int param_3 = obj.pop_front();
*/示例 1:
输入:
["MaxQueue","push_back","push_back","max_value","pop_front","max_value"]
[[],[1],[2],[],[],[]]
输出: [null,null,null,2,1,2]示例 2:
输入:
["MaxQueue","pop_front","max_value"]
[[],[],[]]
输出: [null,-1,-1]限制:
1 <= push_back,pop_front,max_value的总操作数 <= 10000
1 <= value <= 10^5题解
一般来说,如果要快速从队列中找到最大值,那么可以维护一个max在插入新元素时更新最大值。
但是万一出队的操作把这个最大值取走了呢?我们就无法找到下一个最大的值了。
解决的思路是创建一个辅助队列。
public class MaxQueue {
//deque用来存队列
//maxDeque用来存最大值队列
//maxDeque中不一定包含所有队列中的值,
//但其中的值一定是:最大的->第二大的->第三大的....
Deque<Integer> deque, maxDeque;
public MaxQueue() {
deque = new LinkedList<Integer>();
maxDeque = new LinkedList<Integer>();
}
public int max_value() {
if (maxDeque.isEmpty()) return -1;
//maxDeque中第一个就是当前的最大值
return maxDeque.peekFirst();
}
public void push_back(int value) {
deque.addLast(value);
//如果maxDeque队列尾的元素比当前要插入的小,那么就将队尾的出队
while (!maxDeque.isEmpty() && maxDeque.peekLast() < value) maxDeque.removeLast();
//在maxDeque队尾插入
maxDeque.addLast(value);
}
public int pop_front() {
if (deque.isEmpty()) return -1;
int temp = deque.peekFirst();
//如果要出队的这个数恰巧是最大的那个,则将其从maxDeque中也出队
if (temp == maxDeque.peekFirst()) maxDeque.removeFirst();
deque.removeFirst();
return temp;
}
}执行用时:32 ms, 在所有 Java 提交中击败了61.72%的用户
内存消耗:45.8 MB, 在所有 Java 提交中击败了92.88%的用户
参考:如何解决 O(1) 复杂度的 API 设计题 – 队列的最大值 – 力扣(LeetCode) (leetcode-cn.com)
61 扑克牌中的顺子
题目
从若干副扑克牌中随机抽 5 张牌,判断是不是一个顺子,即这5张牌是不是连续的。2~10为数字本身,A为1,J为11,Q为12,K为13,而大、小王为 0 ,可以看成任意数字。A 不能视为 14。
class Solution {
public boolean isStraight(int[] nums) {
}
}示例 1:
输入: [1,2,3,4,5]
输出: True示例 2:
输入: [0,0,1,2,5]
输出: True限制:
数组长度为 5
数组的数取值为 [0, 13]
题解
分析:
- 先对数组执行排序。
- 判别重复: 排序数组中的相同元素位置相邻,因此可通过遍历数组,判断
nums[i] = nums[i + 1]是否成立来判重。 - 获取最大 / 最小的牌: 排序后,数组末位元素
nums[4]为最大牌;元素nums[joker]为最小牌,其中joker为大小王的数量。
public class Solution {
public boolean isStraight(int[] nums) {
int joker = 0;
Arrays.sort(nums); // 数组排序
for (int i = 0; i < 4; i++) {
if (nums[i] == 0) joker++; // 统计大小王数量
else if (nums[i] == nums[i + 1]) return false; // 若有重复,提前返回 false
}
return nums[4] - nums[joker] < 5; // 最大牌 - 最小牌 < 5 则可构成顺子
}
}62 圆圈中最后剩下的数字
题目
0,1,···,n-1这n个数字排成一个圆圈,从数字0开始,每次从这个圆圈里删除第m个数字(删除后从下一个数字开始计数)。求出这个圆圈里剩下的最后一个数字。
例如,0、1、2、3、4这5个数字组成一个圆圈,从数字0开始每次删除第3个数字,则删除的前4个数字依次是2、0、4、1,因此最后剩下的数字是3。
class Solution {
public int lastRemaining(int n, int m) {
}
}示例 1:
输入: n = 5, m = 3
输出: 3示例 2:
输入: n = 10, m = 17
输出: 2限制:
1 <= n <= 10^51 <= m <= 10^6
题解
暴力
public class Solution {
public int lastRemaining(int n, int m) {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < n; i++) {
list.add(i);
}
int index = 0;
while (n > 1) {
index = (index + m - 1) % n;
list.remove(index);
n--;
}
return list.get(0);
}
}执行用时:1347 ms, 在所有 Java 提交中击败了7.02%的用户
内存消耗:40.6 MB, 在所有 Java 提交中击败了12.06%的用户
数学解法
最后只剩下一个元素,假设这个最后存活的元素为 num, 这个元素最终的的下标一定是0 (因为最后只剩这一个元素),
所以如果我们可以推出上一轮次中这个num的下标,然后根据上一轮num的下标推断出上上一轮num的下标,
直到推断出元素个数为n的那一轮num的下标,那我们就可以根据这个下标获取到最终的元素了。推断过程如下:首先最后一轮中num的下标一定是0, 这个是已知的。
那上一轮应该是有两个元素,此轮次中 num 的下标为 (0 + m)%n = (0+3)%2 = 1; 说明这一轮删除之前num的下标为1;
再上一轮应该有3个元素,此轮次中 num 的下标为 (1+3)%3 = 1;说明这一轮某元素被删除之前num的下标为1;
再上一轮应该有4个元素,此轮次中 num 的下标为 (1+3)%4 = 0;说明这一轮某元素被删除之前num的下标为0;
再上一轮应该有5个元素,此轮次中 num 的下标为 (0+3)%5 = 3;说明这一轮某元素被删除之前num的下标为3;….
因为我们要删除的序列为0到n-1, 所以求得下标其实就是求得了最终的结果。比如当n 为5的时候,num的初始下标为3,
所以num就是3,也就是说从0-n-1的序列中, 经过n-1轮的淘汰,3这个元素最终存活下来了,也是最终的结果。总结一下推导公式:(此轮过后的num下标 + m) % 上轮元素个数 = 上轮num的下标
public class Solution {
public int lastRemaining(int n, int m) {
int ans = 0;
//从2开始反推
for (int i = 2; i <= n; i++) {
ans = (ans + m) % i;
}
return ans;
}
}执行用时:4 ms, 在所有 Java 提交中击败了99.98%的用户
内存消耗:35.1 MB, 在所有 Java 提交中击败了83.29%的用户
63 股票的最大利润
题目
假设把某股票的价格按照时间先后顺序存储在数组中,请问买卖该股票一次可能获得的最大利润是多少?
class Solution {
public int maxProfit(int[] prices) {
}
}示例 1:
输入: [7,1,5,3,6,4]
输出: 5
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格。示例 2:
输入: [7,6,4,3,1]
输出: 0
解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。限制:
0 <= 数组长度 <= 10^5
题解
暴力解法
如果不考虑别的因素,那么想要收益最大化,肯定是用最高价格减去最低价格。
但是实际问题需要考虑先后问题。总要先买才能卖。
大致思路:
维护一个minPrice,表示在第i天时的历史最低价格;
维护一个maxProfit,表示在第i天时的最大收益;
进行一次遍历,在遍历的过程中对minPrice和maxProfit进行实时的更新,这样就不存在一个先后问题了。
public class Solution {
public int maxProfit(int[] prices) {
int minPrice = Integer.MAX_VALUE;
int maxProfit = 0;
for (int price : prices) {
if (price < minPrice) {
minPrice = price;
} else if (price - minPrice > maxProfit) {
maxProfit = price - minPrice;
}
}
return maxProfit;
}
}执行用时:1 ms, 在所有 Java 提交中击败了98.58%的用户
内存消耗:38.1 MB, 在所有 Java 提交中击败了69.63%的用户
动态规划
创建一个数组dp,dp[i]表示第i天卖出的最大收益;再定义一个变量cost,用于存放当前最小的成本
public class Solution {
public int maxProfit(int[] prices) {
if (prices.length < 2) return 0; /
// 定义状态,第i天卖出的最大收益
int[] dp = new int[prices.length];
dp[0] = 0; // 初始边界
int cost = prices[0]; // 成本
for (int i = 1; i < prices.length; i++) {
dp[i] = Math.max(dp[i - 1], prices[i] - cost);
// 选择较小的成本买入
cost = Math.min(cost, prices[i]);
}
return dp[prices.length - 1];
}
}执行用时:2 ms, 在所有 Java 提交中击败了56.72%的用户
内存消耗:38.2 MB, 在所有 Java 提交中击败了51.68%的用户
(我觉得这种dp有点蠢,其实上面的暴力就是dp优化掉数组的结果)
64 求1+2+…+n
题目
求 1+2+...+n ,要求不能使用乘除法、for、while、if、else、switch、case等关键字及条件判断语句(A?B:C)。
class Solution {
public int sumNums(int n) {
}
}示例 1:
输入: n = 3
输出: 6示例 2:
输入: n = 9
输出: 45限制:
1 <= n <= 10000
题解
回溯
这到底由于给出了一些限制条件,因此不能用传统的数学公式或for迭代来实现。
而普通的回溯一般都有一个if来进行终止条件的判断,
这题的难点就在于用其他方式来实现回溯终止。
常见的逻辑运算符有三种,即 “与 && ”,“或 || ”,“非 ! ” ;而其有重要的短路效应,如下所示:
if(A && B) // 若 A 为 false ,则 B 的判断不会执行(即短路),直接判定 A && B 为 false
if(A || B) // 若 A 为 true ,则 B 的判断不会执行(即短路),直接判定 A || B 为 true
本题需要实现 “当 n = 1 时终止递归” 的需求,可通过短路效应实现。
n > 1 && sumNums(n – 1) // 当 n = 1 时 n > 1 不成立 ,此时 “短路” ,终止后续递归
public class Solution {
public int sumNums(int n) {
if (n == 0) return 0;
return n + sumNums(n - 1);
}
}执行用时:1 ms, 在所有 Java 提交中击败了32.48%的用户
内存消耗:36 MB, 在所有 Java 提交中击败了8.57%的用户
65 不用加减乘除做加法
题目
写一个函数,求两个整数之和,要求在函数体内不得使用 “+”、“-”、“*”、“/” 四则运算符号。
class Solution {
public int add(int a, int b) {
}
}示例:
输入: a = 1, b = 1
输出: 2提示:
a, b 均可能是负数或 0
结果不会溢出 32 位整数
题解
设两个二进制数a,b
| a | b | 进位(c) | 无进位和(d) |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 0 | 1 | 0 | 1 |
| 1 | 0 | 0 | 1 |
| 1 | 1 | 1 | 0 |
进位规则和与运算一致
无进位和与异或运算规律相同
c=a&b<<1与运算+左移一位
d=a^b异或运算则s=a+b->s=c+d
public class Solution {
public int add(int a, int b) {
int res = 0, c, d;
do {
//进位
c = (a & b) << 1;
//无进位和
d = a ^ b;
//把c重新赋值给a
a = c;
//把d重新赋值给b
b = d;
//当进位=0时跳出循环
} while (c != 0);
res = c + d;
//返回结果
return res;
}
}执行用时:0 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:35.3 MB, 在所有 Java 提交中击败了18.16%的用户
66 构建乘积函数
题目
给定一个数组 A[0,1,…,n-1],请构建一个数组 B[0,1,…,n-1],其中 B[i] 的值是数组 A 中除了下标 i 以外的元素的积, 即 B[i]=A[0]×A[1]×…×A[i-1]×A[i+1]×…×A[n-1]。不能使用除法。
class Solution {
public int add(int a, int b) {
}
}示例:
输入: [1,2,3,4,5]
输出: [120,60,40,30,24]提示:
所有元素乘积之和不会溢出 32 位整数a.length <= 100000
题解
暴力
public class Solution {
public int[] constructArr(int[] a) {
int[] b = new int[a.length];
for (int i = 0; i < b.length; i++) {
b[i] = 1;
for (int j = 0; j < i; j++) {
b[i] *= a[j];
}
for (int j = i + 1; j < b.length; j++) {
b[i] *= a[j];
}
}
return b;
}
}思路应该是没什么问题,但是复杂度太高,超时了
动态规划
| 输出 | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| B[0] | – | A[1] | A[2] | A[3] |
| B[1] | A[0] | – | A[2] | A[3] |
| B[2] | A[0] | A[1] | – | A[3] |
| B[3] | A[0] | A[1] | A[2] | – |
这题实质上就是维护左下角和右上角两个dp数组
状态转移方程:
设左下角为C,右上角为D
C[i]=C[i-1]*A[i-1]
D[i]=D[i+1]*A[i+1]
B[i]=C[i]*D[i]
public class Solution {
public int[] constructArr(int[] a) {
int n = a.length;
if (n == 0)
return new int[]{};
int[] b = new int[n];
int[] c = new int[n];
int[] d = new int[n];
c[0] = 1;
d[n - 1] = 1;
for (int i = 1; i < n; i++) {
c[i] = c[i - 1] * a[i - 1];
}
for (int i = n - 2; i >= 0; i--) {
d[i] = d[i + 1] * a[i + 1];
}
for (int i = 0; i < n; i++) {
b[i] = c[i] * d[i];
}
return b;
}
}执行用时:2 ms, 在所有 Java 提交中击败了52.20%的用户
内存消耗:51 MB, 在所有 Java 提交中击败了67.79%的用户
68 I 二叉搜索树的最近公共祖先
题目
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
}
}示例 1:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
输出: 6
解释: 节点 2 和节点 8 的最近公共祖先是 6。示例 2:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
输出: 2
解释: 节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。说明:
所有节点的值都是唯一的。p、q 为不同节点且均存在于给定的二叉搜索树中。
题解
把最近公共祖先的定义理解提取一下:设节点 rootroot 为节点 p,q 的某公共祖先,若其左子节点 root.left 和右子节点 root.right 都不是 p,q 的公共祖先,则称 root 是 “最近的公共祖先” 。
根据这个定义,若root是p,q的最近公共祖先,可以有以下推论:
- p,q在root的子树中,并且在root的异侧
- p=root,q在root的子树中
- q=root,p在root的子树中
而这题又有两个很重要的条件:树为二叉搜索树;树的节点的值唯一。
根据这两个条件,有以下推论
- 若root.val<p.val,则p在root的右子树中
- 若root.val>p.val,则p在root的左子树中
- 若root.val=p.val,则p就是root
迭代
public class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
while (root != null) {
//当root的值比p和q都小,说明p,q都在root的右子树上
//此时root的右子树中必然有更近的公共祖先,因此root向右迭代
if (root.val < p.val && root.val < q.val)
root = root.right;
//向左迭代同理
else if (root.val > p.val && root.val > q.val)
root = root.left;
//当p,q在root的异侧时,root一定是他们的最近公共祖先,跳出循环
else
break;
}
return root;
}
}执行用时:5 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:38.8 MB, 在所有 Java 提交中击败了85.78%的用户
递归
思路和迭代类似
public class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
//向右递归
if (root.val < p.val && root.val < q.val)
return lowestCommonAncestor(root.right, p, q);
//向左递归
if (root.val > p.val && root.val > q.val)
return lowestCommonAncestor(root.left, p, q);
return root;
}
}执行用时:5 ms, 在所有 Java 提交中击败了100.00%的用户
内存消耗:39 MB, 在所有 Java 提交中击败了59.57%的用户
68 II 二叉树的最近公共祖先
题目
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
/**
* Definition for a binary tree node.
* public class TreeNode {
* int val;
* TreeNode left;
* TreeNode right;
* TreeNode(int x) { val = x; }
* }
*/
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
}
}示例 1:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
输出: 6
解释: 节点 2 和节点 8 的最近公共祖先是 6。示例 2:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
输出: 2
解释: 节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。说明:
所有节点的值都是唯一的。p、q 为不同节点且均存在于给定的二叉搜索树中。
题解
把最近公共祖先的定义理解提取一下:设节点 rootroot 为节点 p,q 的某公共祖先,若其左子节点 root.left 和右子节点 root.right 都不是 p,q 的公共祖先,则称 root 是 “最近的公共祖先” 。
根据这个定义,若root是p,q的最近公共祖先,可以有以下推论:
- p,q在root的子树中,并且在root的异侧
- p=root,q在root的子树中
- q=root,p在root的子树中
上面这些都和68 I一样。但这题和68 I的区别在于,所给的树不是二叉搜索树。
由于没有了这个关键条件,这题只能用递归的方法写了。
递归(先序遍历)
public class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if (root == null) return null;
//不仅是特判,也是后续递归的回溯条件
//当后续递归遇到p,q时,就会回溯
if (p == root || q == root) return root;
//一直向左子树遍历
//如果左边有p或q,则将其赋值给left
//注意left的值是向左遍历的过程中遇到的第一个p或q
TreeNode left = lowestCommonAncestor(root.left, p, q);
//一直向右子树遍历
//如果右边有p或q,则将其赋值给right
//注意right的值是向右遍历的过程中遇到的第一个p或q
TreeNode right = lowestCommonAncestor(root.right, p, q);
//若left==null,说明p,q都在root的右子树中
//则右边遇到的第一个p或q就是最近公共祖先
if (left == null) return right;
//若right==null,说明p,q都在root的左子树中
//则左边遇到的第一个p或q就是最近公共祖先
else if (right == null) return left;
//否则说明p和q在root的异侧,那root必定是最近公共祖先
else return root;
}
}执行用时:7 ms, 在所有 Java 提交中击败了75.96%的用户
内存消耗:39.6 MB, 在所有 Java 提交中击败了72.29%的用户