浅析网络IO模型
前言
I/O 泛指的是 CPU 向 I/O设备(硬盘、网卡)中读取/写入数据。而本文主要介绍的是网络 I/O,也就是借助于 Socket Api ,从网卡中读取数据。
Unix网络编程中的五种IO模型
一个I/O操作通常分为两个阶段:
- 等待数据准备(从磁盘/网卡中读取数据到内核空间中的缓冲区)。
- 从内核空间中的缓冲区向用户空间复制数据。
阻塞式I/O
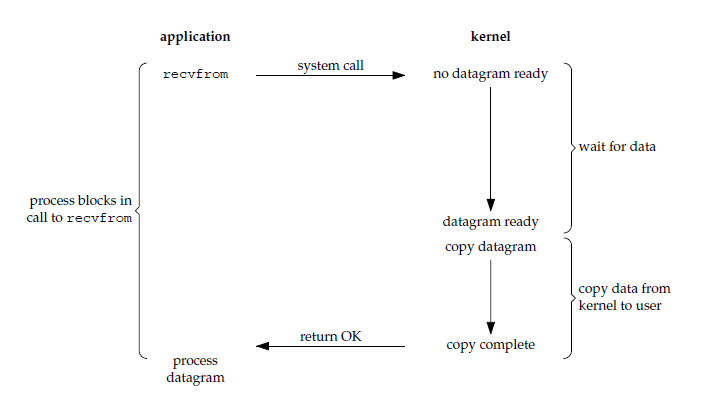
假设在服务器上有一个应用需要接收客户端通过socket传递的数据。
1 | //服务端应用程序伪代码: |
通过上述伪代码,不难发现阻塞I/O有如下几个问题:
- 在同一时间,只能接收一个客户端的连接,如果应用程序是单线程的,就无法实现并发。
- 其他客户端必须等待前一个客户端与服务端建立连接+传输数据+逻辑操作全部完成后,才能与服务端执行连接。
- 对于服务端来说,虽然应用程序被阻塞,但是CPU任然可以执行其他操作,因此CPU利用率并不低。
对于阻塞式IO来说,如果想要提高并发能力,同时处理多个服务端请求,就需要对每个服务端的TCP请求新建一个线程。如果客户端较多,则会给服务端带来很大的内存和CPU压力。
非阻塞式I/O
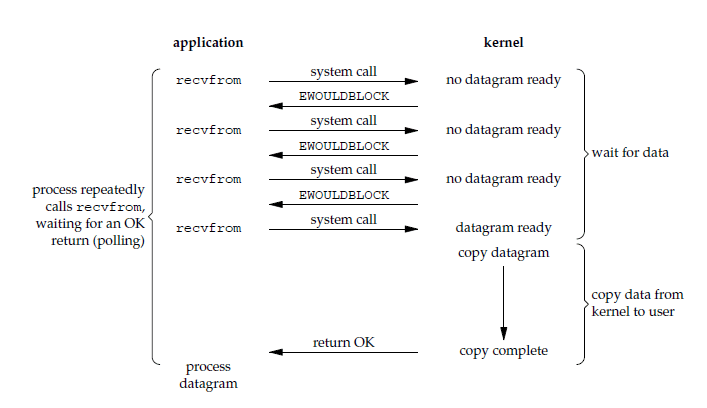
非阻塞式IO会让accept、read等系统调用不阻塞应用,而是直接返回一个值。可以通过这个值的合法性来判断是否调用成功。
1 | //服务端应用程序伪代码: |
上述伪代码中服务端主要任务是不断接收socket连接并接收其写入的内容,然后轮询判断每个socket的fd中的数据是否准备完毕,准备完毕后就执行逻辑操作。
非阻塞式IO的优点:
- 单线程即可处理多个socket连接。
非阻塞式IO的缺点:
- 需要不断进行系统调用(read函数),导致频繁的内核态、用户态切换,因此CPU利用率反而比阻塞IO低。
I/O复用
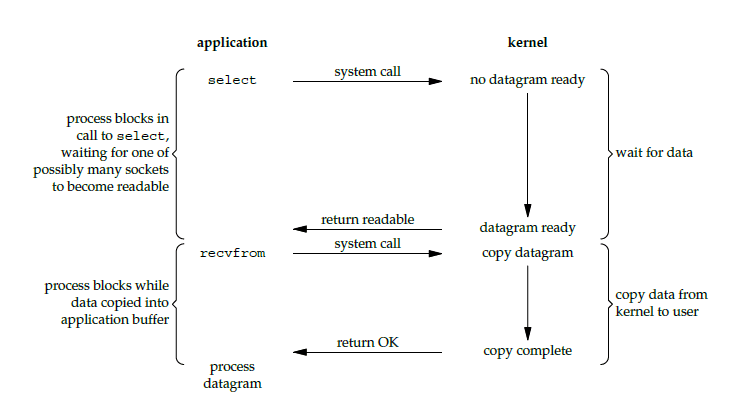
IO复用即让一个线程可以监听多个IO。
select
select是Unix提供的一个系统调用函数,其原理与非阻塞式IO相同,只不过是将轮询fd_list的过程从用户态进行系统调用变成直接在内核态判断。select函数是阻塞的。
1 | //服务端应用程序伪代码: |
select的缺点:
- 在调用 select 的时候,需要将 fd_list 拷贝到内核空间,产生性能开销。
- 在内核态中使用轮询 fd_list 的方式进行监控,占用CPU资源。
- select 返回后,用户态并不知道是哪个 fd 准备就绪,需要再次遍历。
- select 默认只能接收1024个 fd。
poll
poll 和 select 类似,只是其中的数据结构实现方式不同。
epoll
epoll 就是为了解决 poll 和 select 的问题而推出的最新的IO复用函数。
不同于 poll/select 在内核态中轮询,epoll 是基于事件回调和中断的。
epoll包含三个函数:
epoll_create:在内存中创建一个
struct eventpoll的对象。eventpoll 包含三块内容:
- wq:等待队列。存储阻塞在epoll上的用户进程。
- rbr:红黑树,节点为
struct epitem。epitem中有两个重要的元素:socket_fd、ep_poll_callback(ep_poll_callback是一个回调函数,作用是将这个socket_fd添加到 rdllist 并唤醒等待队列中的元素)。 - rdllist:就绪队列。存储准备就绪的
socket_fd。
epoll_ctl:注册
socket。当使用
epoll_ctl注册socket的时候,内核会将socket封装为一个 epitem ,并添加到 rbr 中。epoll_wait:获取就绪事件。就绪的事件通过参数回传。
epoll_wait 被调用时,如果 rdllist 中有数据则返回;无数据则将当前线程封装后添加到 wq 中,并阻塞当前线程。
客户端发送数据并被 epoll 接收的流程:
- 客户端发送数据包到网卡。网卡通过DMA把数据拷贝至内存缓冲区,拷贝完成后发送中断信号。
- CPU接收到中断信号,通过数据包的IP和端口号找到 socket,将数据添加到 socket 中。
- CPU触发回调函数 ep_poll_callback,将 socket 添加到 rdllist 并唤醒等待队列中的线程。
- 线程继续执行。
epoll的优点:
- 在 socket 连接较多的情况下,性能优于 select/poll。
epoll的缺点:
- epoll是 linux2.6 内核添加的功能,而 select/poll 则是 posix 规范的接口,因此 epoll 只能用于 linux 内核,移植性较差。
边缘触发和水平触发
边缘触发和水平触发是两种不同的 I/O 处理方式。它们都有各自的优缺点。
- 边缘触发(edge-triggered)模式下,选择器会在事件发生时立即触发通知,并且只会触发一次。这种方式可以确保我们在处理事件时不会错过任何数据,但是它可能会导致多次处理同一个事件。
- 水平触发(level-triggered)模式下,选择器会在事件发生时立即触发通知,但是会持续触发,直到事件处理完毕。这种方式可以避免多次处理同一个事件,但是它可能会导致数据丢失,因为我们可能在事件发生后处理数据时会错过一些数据。
通常情况下,我们应该根据具体情况来选择合适的 I/O 处理方式。对于实时性要求较高的应用,我们可以使用边缘触发模式;对于需要保证数据不丢失的应用,我们可以使用水平触发模式。
信号驱动I/O
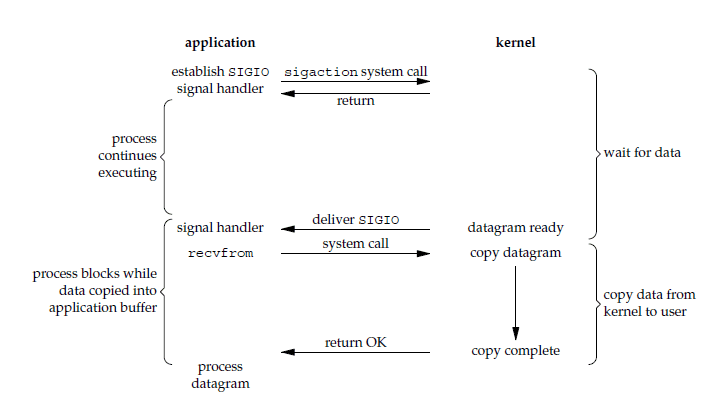
应用进程使用 sigaction 系统调用,内核立即返回,应用进程可以继续执行,也就是说等待数据阶段应用进程是非阻塞的。内核在数据到达时向应用进程发送 SIGIO 信号,应用进程收到之后在信号处理程序中调用 recvfrom 将数据从内核复制到应用进程中。
相比于非阻塞式 IO 的轮询方式,信号驱动 IO 的 CPU 利用率更高。
异步I/O
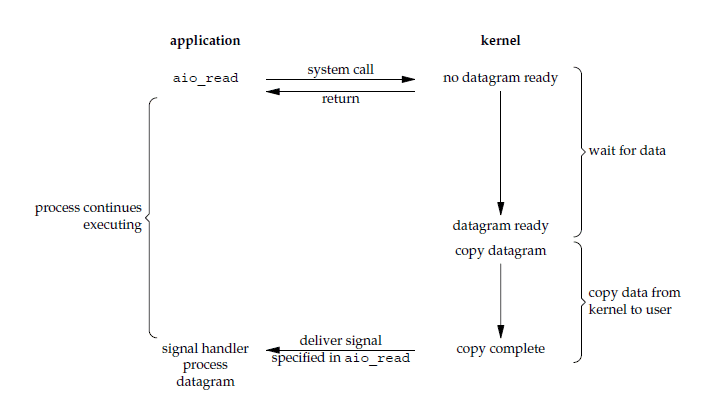
进行 aio_read 系统调用会立即返回,应用进程继续执行,不会被阻塞,内核会在所有操作完成之后向应用进程发送信号。
异步 IO 与信号驱动 IO 的区别在于,异步 IO 的信号是通知应用进程 IO 完成,而信号驱动 IO 的信号是通知应用进程可以开始 IO。
Java中的IO模型
Java中的几种IO API:
- 阻塞同步IO:BIO
- 非阻塞同步IO:NIO
- 非阻塞异步IO:AIO
BIO和NIO的本质区别在于,BIO是面向流(Stream)的,NIO是面向缓冲区(Buffer)的。
面向流意味着只能单向读取或写入数据,并且每次只能从流中写入/读取一个或多个字节,读取和写入时要阻塞至完毕;面向缓冲区则可以双向读取写入,并且数据将会被先读入到缓冲区中,然后再处理。面向缓冲相比于面向流,更加灵活。
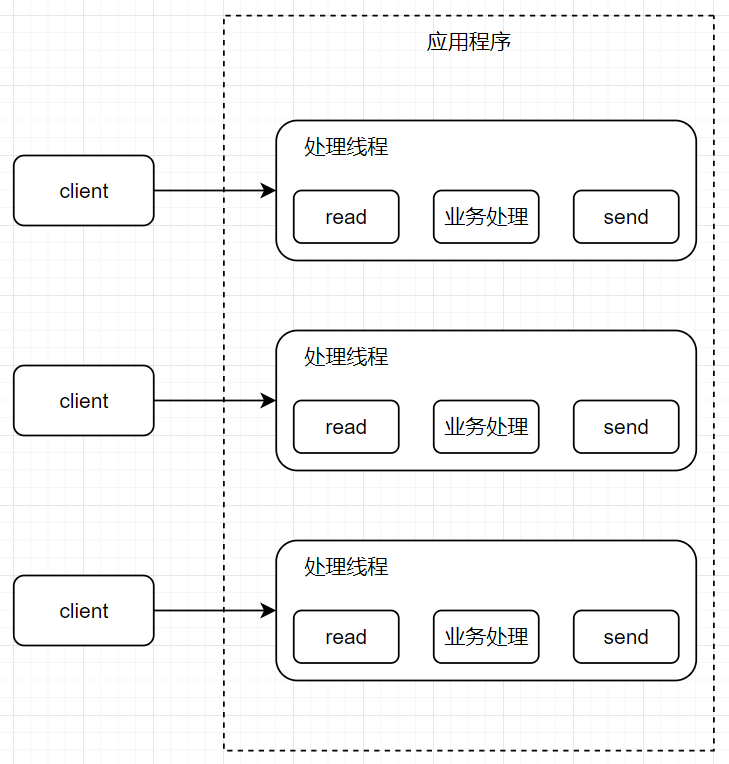
BIO-传统IO模型
传统IO模型:
1 | public class Solution { |
特点:
- 数据传输采用阻塞式IO。
- 每个连接需要独立的线程去执行读取、业务逻辑、写入的操作。
- 适用于业务逻辑耗时长,低负载、低并发的场景。
缺点:
- 服务端的并发量和线程数成正比。
- 由于每个连接都需要独立的线程去处理,因此同时可能会有大量线程被创建,然而这些线程实际上大部分是事件都处于阻塞状态(阻塞在read())。
- 由于accept()是阻塞的,因此可能会存在后面一个连接的请求已经到达,然而前一个连接还没有建立完成,导致接收连接的线程阻塞。(举个例子,假设 ServerSocket 建立每个连接耗时4ms,那么即使CPU性能再高,也会受限于网络的瓶颈,每秒钟最多处理250个连接)
NIO-Reactor模型
NIO中的几个概念:
Buffer(缓冲区)
缓冲区本质上是一块可以读写数据的内存,这块内存被包装成 NIO 的 Buffer 对象,并对外提供一系列方法用于访问该块内存。
对应于
java.nio.Buffer抽象类。Channel(通道)
通道类似 BIO 中的 Stream,用于向 Buffer 中读取或写入数据。
对应于
java.nio.channels.Channel接口。Selector(选择器)
选择器可以检查一个或多个通道,并确定哪些通道已经准备好进行读写。通过 Selector,一个单独的线程可以管理多个 Channel,从而管理多个连接。不过不是所有的 Channel 都可以被 Selector 复用,必须要继承了 SelectableChannel。
对应于
java.nio.channels.Selector抽象类。
NIO特点:
- 每个 Channel 对应一个 Buffer。
- 一个线程对应一个 Selector,一个 Selector 对应多个 Channel。
- Buffer 是一个内存块,底层是数组,可以切换读写模式(实际上是改变参数)。
Buffer
Buffer的实现类有:ByteBuffer、CharBuffer、ShortBuffer、IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer。
无论是哪一种,管理方式都一致,都是通过 allocate(int capacity) 来获取 Buffer。
Buffer 的几个重要属性
- capacity:Buffer的最大容量,创建后不能更改。
- limit:缓冲区可以操作的数据大小,index 大于 limit 的数据不能读写。limit 不能为并且不能大于 capacity。在写模式下,limit 等于 capacity;在读模式下,limit 等于当前容量。
- position:下一个要读取或写入的数据的 index。
- mark:标记,可以通过
mark()方法记录当前 position,然后通过reset()恢复 position 的位置。
Buffer 的几个重要方法
Buffer clear():清空 Buffer,读模式转变为写模式(position设为0,limit设为capacity,mark设为-1)并返回。Buffer flip():写模式转变为读模式(limit设为position,position设为0,mark设为-1)并返回。get():获取当前数据类型的一个数据。put():存储当前数据类型的一个数据。
Buffer 读写数据的步骤
- 写入数据。
- 调用
flip()切换读取模式。 - 读取数据。
- 调用
clear()清除数据。
直接缓冲区和非直接缓冲区
直接缓冲区:通过
allocate()Direct创建缓冲区,缓冲区建立在直接内存中。直接内存在IO处理时的性能更高,但申请直接内存会耗费更多性能。一般在有大量数据需要存储并且生命周期很长,或者有频繁IO操作时,适合使用直接缓冲区。
非直接缓冲区:通过
allocate()创建缓冲区,缓冲区建立在JVM堆内存中。
Channel
Channel类似于BIO中的流,用于在支持 Channel 的两个结点中传递数据。但是 Channel 本身并不存储数据,需要配合 Buffer 使用。Channel 的实现类有:FileChannel、SocketChannel、ServerSocketChannel、DatagramChannel。
获取 Channel 对象的方法
- 调用支持 Channel 的对象的
getChannel()。支持 Channel 的对象有:- FileInputStream
- FileOutputStream
- RandomAccessFile
- DatagramSocket
- Socket
- ServerSocket
- 通过 Channel 的实现类的静态方法
open()。 Files.newByteChannel()
Channel 的几个重要方法
int read(Buffer dst):从 Channel 中读取数据到 Buffer。int write(Buffer src):将 Buffer 中的数据写入到 Channel 中。
使用 Channel 完成文件复制的例子
1 | public class Solution { |
Selector
Selector 是 Java NIO 中的多路复用器。将 SelectableChannel 注册到 Selector 中,就可以通过一个 Selector 监听多个 SelectableChannel。Selector 和 SelectableChannel 是多对多的关系。
Selector的基本使用
创建:
Selector.open()。由于多路复用需要操作系统提供底层的支持,因此在不同的环境下会提供不同的 Selector 实例。例如 Windows-JDK 下会提供sun.nio.ch.WindowsSelectorImpl,Linux-JDK 下会提供sun.nio.ch.EPollSelectorImpl。注册:
1
2channel.configureBlocking(false);
SelectionKey key = channel.register(selector, Selectionkey.OP_READ);注册到 Selector 的 Channel 必须是非阻塞的,否则会抛出 IllegalBlockingModeException。
register()的第二个参数表示需要监听的事件,分别为Connect、Accept、Read、Write,如果需要监听多个事件,可以用|分隔。SelectionKey:
注册后会返回 SelectionKey 的对象,这个对象表示了一个 Channel 和 一个 Selector 的对应关系。
1
2
3
4
5key.attachment(); //返回SelectionKey的attachment,attachment可以在注册channel的时候指定。
key.channel(); //返回该SelectionKey对应的channel。
key.selector(); //返回该SelectionKey对应的Selector。
key.interestOps(); //返回监听的事件的bit mask,对应channel.register()的第二个参数
key.readyOps(); //返回已准备就绪的事件的bit mask获取就绪的Channel:
先调用 select() 获取准备就绪的通道数量。select() 相关的几个方法:
- select():阻塞获取就绪的通道数量。
- select(long timeout):阻塞获取就绪的通道数量,如果超时则返回0。
- selectNow():非阻塞获取就绪通道数量。
(select() 表示从上次调用 select() 后新增了多少已准备就绪的通道)
如果 select() 返回值不为0,说明有已准备就绪的通道,调用 selector.selectedKeys() 获取通道集合。
NIO基本服务端代码编写
1 | public class Solution { |
特点:
- 由于是非阻塞IO,每当一个连接请求到达,只需要将其注册到 Selector 中,因此单线程可以一直处理连接请求。
- 读取数据和逻辑操作与BIO一样,因此NIO的优势在于对连接的处理,即在等待某个连接建立的过程中可以继续和其他请求建立连接。
- 适用于业务逻辑耗时短,高负载高并发的场景
Reactor模型
Reactor模型是基于 NIO 提出的一套IO模型。本质上是把上面编写的NIO服务端代码进行组件拆分和抽象化:
- Reactor:负责接收用户端连接
- Acceptor:负责建立连接
- Hispatch:负责处理请求
客户端测试代码:
1 | public class Client { |
单Reactor单线程
单Reactor单线程实际上就是之前的NIO服务端代码。
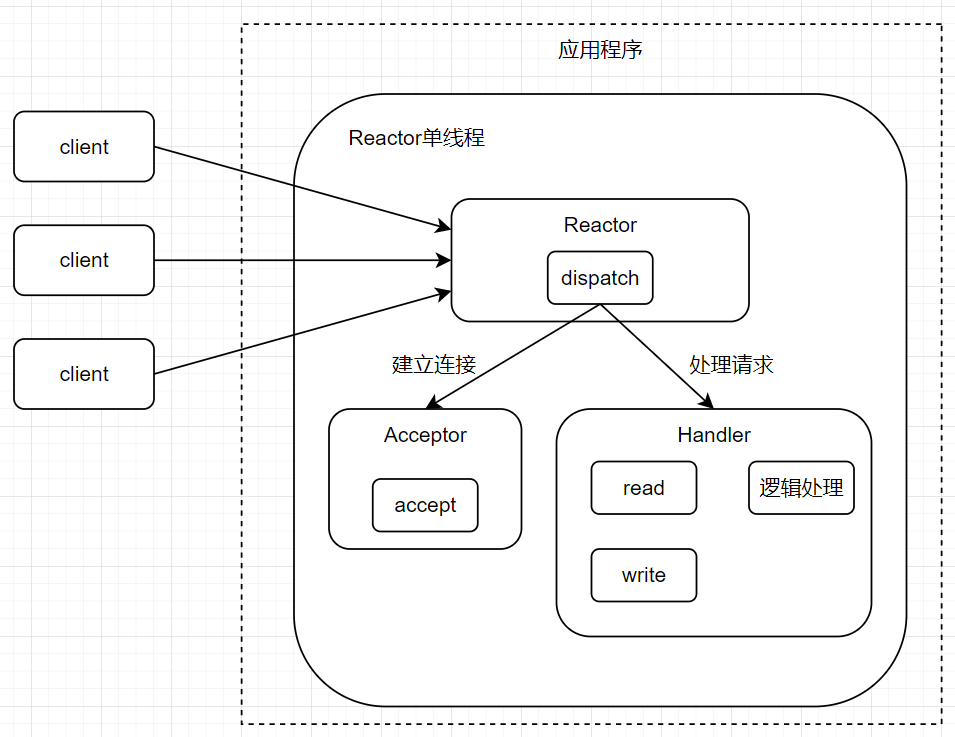
流程:
- Reactor 对象使用 select 监听客户端连接请求,触发事件后将其交给 dispatch() 分发
- 如果是建立连接请求事件,则分发给 Acceptor 通过 accept() 处理连接请求事件,然后创建 Handler 处理后续事件。
- 如果不是建立连接事件,则会分发给之前创建的 Handler 处理。
- Handler 负责处理读取、业务逻辑、写入。
1 | public class Reactor implements Runnable { |
1 | public class Acceptor implements Runnable { |
1 | public class Handler implements Runnable { |
单Reactor多线程
在上面的单Reactor单线程模型中,Handler部分执行代码都是单线程的,因此可能会导致一个Handler执行事件过久而阻塞其他的Acceptor和Handler,即服务端同时能进行逻辑处理的用户端只有一个。因此可以考虑在Handler部分加入线程池。
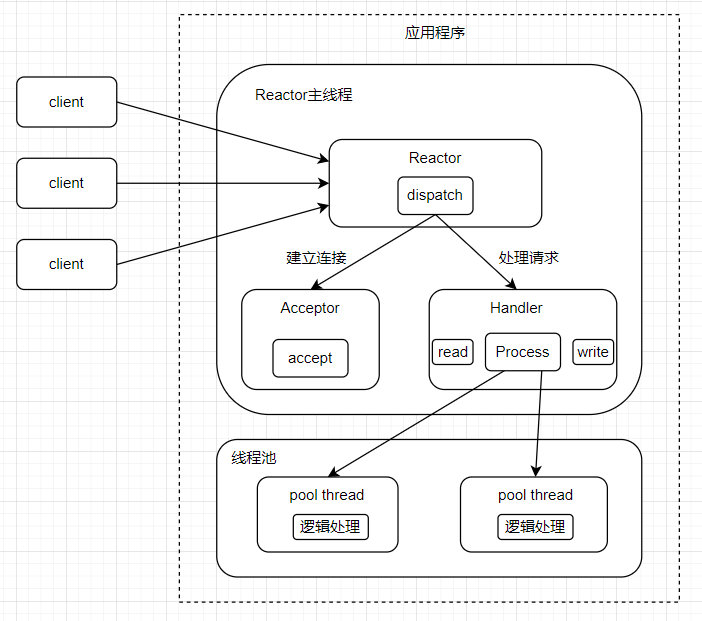
Reactor和Acceptor部分代码不变,Handler代码变动:
1 | public class Handler implements Runnable { |
1 | public class Process implements Runnable { |
主从Reactor模型
在上面的单Reactor多线程模型中,虽然把逻辑处理交给了线程池,但是读写操作还是由 Reactor(主线程)来处理。因此单个 Reactor 需要同时处理连接请求和读写,执行压力很大。于是便有了主从 Reactor 模型。其中一个Reactor负责处理连接,另一个负责处理客户端的读写。
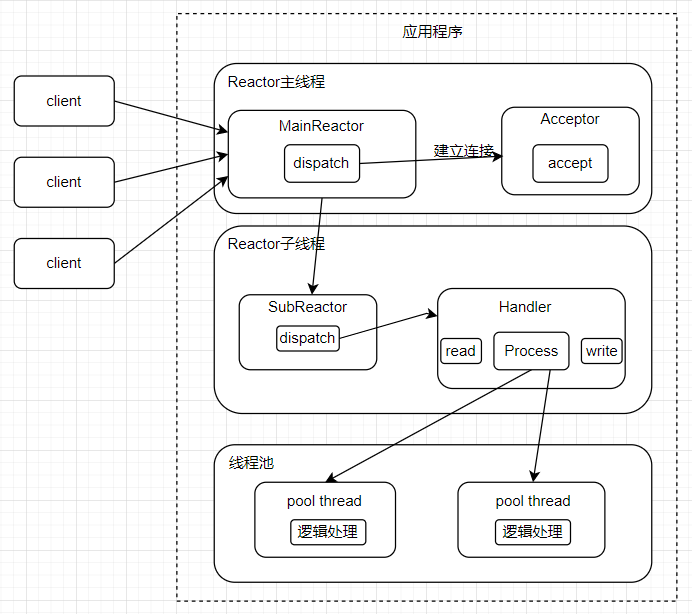
- Reactor 主线程 MainReactor 对象通过 Select 监控建立连接事件,收到事件后通过 Acceptor 接收,处理建立连接事件;
- Acceptor 处理建立连接事件后,MainReactor 将连接分配 Reactor 子线程给 SubReactor 进行处理;
- SubReactor 将连接加入连接队列进行监听,并创建一个 Handler 用于处理各种连接事件;
- 当有新的事件发生时,SubReactor 会调用连接对应的 Handler 进行响应;
- Handler 通过 Read 读取数据后,会分发给后面的 Worker 线程池进行业务处理;
- Worker 线程池会分配独立的线程完成真正的业务处理,如何将响应结果发给 Handler 进行处理;
- Handler 收到响应结果后通过 Send 将响应结果返回给 Client。
参考:
【并发】IO多路复用select/poll/epoll介绍_哔哩哔哩_bilibili
Linux的5种IO模型梳理 - 知乎 (zhihu.com)
「Linux」——select和epoll详解 - 知乎 (zhihu.com)
图解 | 深入揭秘 epoll 是如何实现 IO 多路复用的! (qq.com)
聊聊Linux 五种IO模型 - 简书 (jianshu.com)