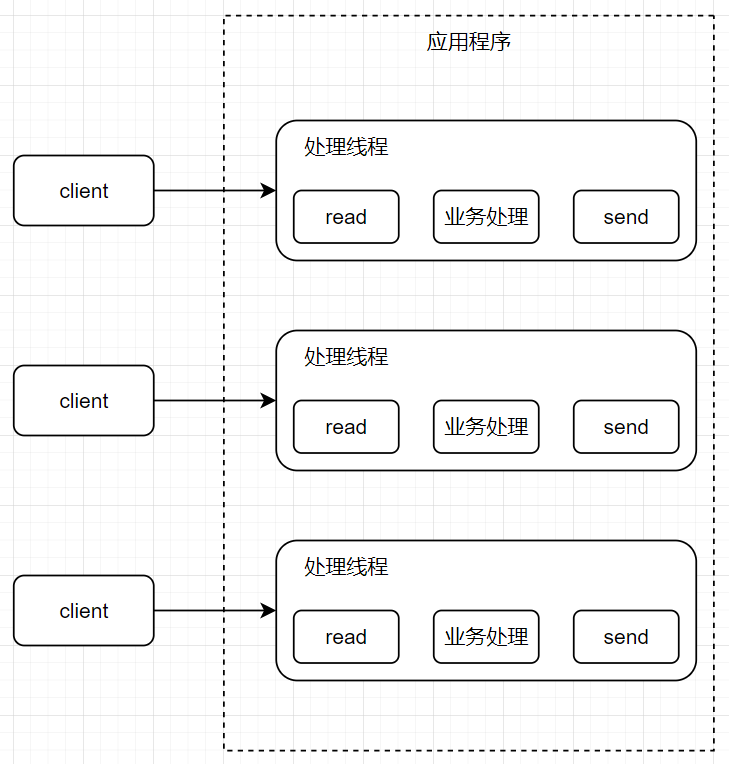
虚拟线程(有栈协程)对于Java的意义 1.传统同步线程模型 在传统的 servlet 生态中,线程模型一般是 thread per request,即每个请求分配一个线程,这个线程负责整个请求的生命周期。
有个很直观的理解:ThreadLocal–在一次请求过程中,可以在请求上游往 ThreadLocal set 一些数据,比如可以存 userId、trace 等;在请求下游时直接调用 threadLocal.get() 即可获取。
在这种线程模型中,想要承载更多请求,就需要添加更多线程。更多的线程意味着带来更多的资源占用:
2.异步&响应式线程模型 为了避免创建和阻塞过多的内核线程,我们需要一种方式提高线程利用率:当遇到某些阻塞IO操作,将线程迁移走以执行其他任务。
这里贴一张 netty 中的 eventloop 调用逻辑图,帮助理解:
在这种模式中,线程不存在上下文切换的开销,同时单个线程按照 Reactor 模型也可以服务多个连接&请求。
事实上已经有很多框架提供了这部分能力,例如 Netty、Vert.x、Quarkus。
这些框架的代码风格通常是 future 套 future,将异步回调操作串在一起,例如这段用 Vert.x 的示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class MainVerticle extends AbstractVerticle { @Override public void start (Promise<Void> startPromise) throws Exception { Router router = Router.router(vertx); router.route().handler(context -> { String address = context.request().connection().remoteAddress().toString(); MultiMap queryParams = context.queryParams(); String name = queryParams.contains("name" ) ? queryParams.get("name" ) : "unknown" ; context.json( new JsonObject () .put("name" , name) .put("address" , address) .put("message" , "Hello " + name + " connected from " + address) ); }); vertx.createHttpServer() .requestHandler(router) .listen(8888 ) .onSuccess(server -> { System.out.println("HTTP server started on port " + server.actualPort()); startPromise.complete(); }) .onFailure(throwable -> { throwable.printStackTrace(); startPromise.fail(throwable); }); } }
响应式的弊端:
概念众多,难以理解 。想要使用响应式的生态,有很多概念需要学习,此外代码层层嵌套,势必会形成回调地域,难以维护。
无堆栈信息 。响应式的 api 都是基于事件回调的,当产生阻塞 IO 时,注册完回调后,原有的调用栈栈帧就被弹出了;当阻塞 IO 结束后,触发回调时,就已经失去了原有的堆栈上下文。这意味着如果在这过程中发生异常,我们将无法使用类似 stacktrace 的方式定位调用来源和调用上下文。此外,在 IDE 中也无法进行 step by step 的 debug,我们往往需要把断点打在某个回调中。与现有同步生态不兼容 ,体现在两方面:
现有的阻塞调用需要全部重写:如果我们的业务逻辑编写在同步的生态上,那么想要迁移到响应式的生态并不是一件容易的事。响应式框架大多是基于 eventloop 的,eventloop 中最重要的原则就是:不要阻塞 eventloop 。以 mysql 数据库访问为例,我们现有的同步生态都是阻塞的,想要迁移到响应式的生态,意味着我们需要按照 mysql 的协议重写一套响应式的客户端。虽然大部分响应式框架都提供了一套现有的能力(例如 vetr.x 的 mysqlclient ),但是迁移仍然需要成本。
线程上下文失效:在响应式的编程模型下,一个线程本质上会在多个请求之间交错处理。这很好理解,当 A 请求先到达后,线程优先执行 A 请求的逻辑;此时线程 B 到达,进入了阻塞队列等待线程处理;当线程处理 A 请求到一半,A 进入了阻塞 IO,那么线程将会切换到 B 请求执行逻辑。此时,一些基于 threadlocal 的线程上下文变量就将失效,我们无法保证某个线程“专一”于一个请求,类似于 MDC 的技术将无法使用。
3.内核线程和用户线程 操作系统中的线程模式大致可以分为三种:
内核线程模式:程序的线程和操作系统提供的内核线程是 1:1 的关系
用户线程模式:程序的线程和操作系统提供的内核线程是 n:1 的关系
混合线程模式:程序的线程和操作系统提供的内核线程是 n:m 的关系
实际上在 java 中,用户线程模型出现早于内核线程。Linux 2.6 之前,操作系统只能提供单线程能力,java 使用的是一种名为“绿色”线程的用户线程模型:将主线程运行在 JVM 中,程序中创建用户线程执行多个任务,本质上是单核并发。
后来随着多核技术的兴起,Linux 也提供了多线程的能力,这时“绿色”线程的劣势就暴露出来了,它本质上还是只能使用操作系统的单核进行并发,无法充分利用多核进行并行操作,并且所有的线程阻塞、调度逻辑都需要由 java 实现,而不能使用操作系统的能力。
此时 java 就抛弃了这种古早的线程模型,转为了内核线程模式。
然而内核线程模式也有缺点,创建、销毁涉及操作系统资源的分配和管理,上下文切换涉及系统调用、用户态与内核态的切换,而且一个系统中同时存在的线程数量也有上限。
随着并发量的提高,java 中重新提供用户线程模型的诉求日益增加,于是就有了 jdk21 带来的虚拟线程。
4.无栈协程和有栈协程 从概念上来看,虚拟线程属于用户线程模型,并且可以被视为协程的一种实现。协程是一个轻量化、用户态的执行单元,它可以模拟线程的执行上下文。与传统的线程相比,协程在等待 I/O 等操作时能够被挂起,让载体线程去执行其他协程任务,从而提高资源利用率。
在响应式编程模型中,我们通过异步事件的方式不断切换执行的方法,目的也是在保持线程的活跃性而非阻塞。虽然响应式编程允许在回调函数的作用域中附带上下文信息,但这种方式在复杂场景中可能导致“回调地狱”,使得代码的可读性和可维护性下降。相对而言,协程可以够附带清晰的上下文信息,允许在更大的作用域内管理状态和控制流。这种结构化的上下文管理使得协程在编写异步代码时更加直观和易于维护。
回顾内核线程模式,在这种模式中,操作系统负责内核线程上下文的的存储、恢复、切换;同理,在协程中,关键问题就在于怎么存储、恢复、切换协程的上下文。从协程的实现原理来区分,大致可以分为有栈协程和无栈协程。这里先给出一些简单的概念,后文将举例解析:
有栈协程:每个协程有一个独立的调用栈(类似方法的调用栈)可以用于存储调用的上下文;当有栈协程被挂起后,会将调用栈的完整信息保留。这种模式需要语言底层支持协程原语。
无栈协程:每个协程没有单独的调用栈,它的调用上下文存储在堆中,并通过状态机管理。这种模式一般通过状态机、回调实现,无需底层支持。
以 kotlin 为例的无栈协程 kotlin 基于 jvm,号称 better java,它最重量级的特性就是协程。而我们知道,在 jdk21 之前,jvm 底层并不支持协程原语,所以 kotlin 中的协程很显然只能是无栈协程的实现。
看这段 kotlin 代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package org.exampleimport kotlinx.coroutines.*suspend fun requestToken () println("当前requestToken执行线程为:${Thread.currentThread()} " ) delay(1000 ) return "token" } suspend fun fetchData (token : String ) println("当前fetchData执行线程为:${Thread.currentThread()} " ) delay(1000 ) return "$token :success" } fun main () launch { var token = requestToken(); var fetchData = fetchData(token) println(fetchData) } println("当前main执行线程为:${Thread.currentThread()} " ) delay(5000 ) }
这段代码中,用 suspend 关键字定义了两个可被挂起的方法 fetchData,在这个方法中通过 delay 模拟了耗时的阻塞操作。在主线程中,调用 fetchData 后,fetchData 中执行到阻塞逻辑时,该方法就会被挂起,并让出线程控制权,以便其他协程或任务可以在同一线程上并发执行;当阻塞结束后,将恢复 fetchData 方法,并且继续向下执行。
上述代码看起来和平时的同步阻塞代码几乎一致,你可以 try catch,甚至可以在 idea 中像同步代码一样 step by step 地 debug。
但是,kotlin 的协程并不是完美的,让我们来看下看似美好的背后是什么。上面的代码片段实际等价于:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 package org.exampleimport kotlinx.coroutines.*fun requestToken (callback: (String ) -> Unit ) println("当前requestToken执行线程为:${Thread.currentThread()} " ) GlobalScope.launch { delay(1000 ) callback("token" ) } } fun fetchData (token: String , callback: (String ) -> Unit ) println("当前fetchData执行线程为:${Thread.currentThread()} " ) GlobalScope.launch { delay(1000 ) callback("$token :success" ) } } fun main () requestToken { token -> fetchData(token) { fetchDataResult -> println(fetchDataResult) } } println("当前main执行线程为:${Thread.currentThread()} " ) delay(5000 ) }
也可以将其反编译为 java 代码,一睹真容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 package org.example;import kotlin.Metadata;import kotlin.ResultKt;import kotlin.Unit;import kotlin.coroutines.Continuation;import kotlin.coroutines.CoroutineContext;import kotlin.coroutines.intrinsics.IntrinsicsKt;import kotlin.coroutines.jvm.internal.ContinuationImpl;import kotlin.jvm.functions.Function2;import kotlinx.coroutines.BuildersKt;import kotlinx.coroutines.CoroutineScope;import kotlinx.coroutines.CoroutineStart;import kotlinx.coroutines.DelayKt;import org.jetbrains.annotations.NotNull;import org.jetbrains.annotations.Nullable;@Metadata( mv = {2, 0, 0}, k = 2, xi = 48, d1 = {"\u0000\u0012\n\u0000\n\u0002\u0010\u000e\n\u0002\b\u0003\n\u0002\u0010\u0002\n\u0002\b\u0003\u001a\u0016\u0010\u0000\u001a\u00020\u00012\u0006\u0010\u0002\u001a\u00020\u0001H\u0086@¢\u0006\u0002\u0010\u0003\u001a\u0006\u0010\u0004\u001a\u00020\u0005\u001a\u000e\u0010\u0006\u001a\u00020\u0001H\u0086@¢\u0006\u0002\u0010\u0007¨\u0006\b"}, d2 = {"fetchData", "", "token", "(Ljava/lang/String;Lkotlin/coroutines/Continuation;)Ljava/lang/Object;", "main", "", "requestToken", "(Lkotlin/coroutines/Continuation;)Ljava/lang/Object;", "kotlin-demo"} ) public final class MainKt { @Nullable public static final Object requestToken (@NotNull Continuation $completion) { Continuation $continuation; label20: { if ($completion instanceof <undefinedtype>) { $continuation = (<undefinedtype>)$completion; if (($continuation.label & Integer.MIN_VALUE) != 0 ) { $continuation.label -= Integer.MIN_VALUE; break label20; } } $continuation = new ContinuationImpl ($completion) { Object result; int label; @Nullable public final Object invokeSuspend (@NotNull Object $result) { this .result = $result; this .label |= Integer.MIN_VALUE; return MainKt.requestToken((Continuation)this ); } }; } Object $result = $continuation.result; Object var4 = IntrinsicsKt.getCOROUTINE_SUSPENDED(); switch ($continuation.label) { case 0 : ResultKt.throwOnFailure($result); String var1 = "当前requestToken执行线程为:" + Thread.currentThread(); System.out.println(var1); $continuation.label = 1 ; if (DelayKt.delay(1000L , $continuation) == var4) { return var4; } break ; case 1 : ResultKt.throwOnFailure($result); break ; default : throw new IllegalStateException ("call to 'resume' before 'invoke' with coroutine" ); } return "token" ; } @Nullable public static final Object fetchData (@NotNull String token, @NotNull Continuation $completion) { Continuation $continuation; label20: { if ($completion instanceof <undefinedtype>) { $continuation = (<undefinedtype>)$completion; if (($continuation.label & Integer.MIN_VALUE) != 0 ) { $continuation.label -= Integer.MIN_VALUE; break label20; } } $continuation = new ContinuationImpl ($completion) { Object L$0 ; Object result; int label; @Nullable public final Object invokeSuspend (@NotNull Object $result) { this .result = $result; this .label |= Integer.MIN_VALUE; return MainKt.fetchData((String)null , (Continuation)this ); } }; } Object $result = $continuation.result; Object var5 = IntrinsicsKt.getCOROUTINE_SUSPENDED(); switch ($continuation.label) { case 0 : ResultKt.throwOnFailure($result); String var2 = "当前fetchData执行线程为:" + Thread.currentThread(); System.out.println(var2); $continuation.L$0 = token; $continuation.label = 1 ; if (DelayKt.delay(1000L , $continuation) == var5) { return var5; } break ; case 1 : token = (String)$continuation.L$0 ; ResultKt.throwOnFailure($result); break ; default : throw new IllegalStateException ("call to 'resume' before 'invoke' with coroutine" ); } return token + ":success" ; } public static final void main () { BuildersKt.runBlocking$default ((CoroutineContext)null , new Function2 ((Continuation)null ) { int label; private Object L$0 ; public final Object invokeSuspend (Object $result) { Object var4 = IntrinsicsKt.getCOROUTINE_SUSPENDED(); switch (this .label) { case 0 : ResultKt.throwOnFailure($result); CoroutineScope $this$runBlocking = (CoroutineScope)this .L$0 ; BuildersKt.launch$default ($this $runBlocking, (CoroutineContext)null , (CoroutineStart)null , new Function2 ((Continuation)null ) { int label; public final Object invokeSuspend (Object $result) { Object var10000; label17: { Object var4 = IntrinsicsKt.getCOROUTINE_SUSPENDED(); switch (this .label) { case 0 : ResultKt.throwOnFailure($result); Continuation var6 = (Continuation)this ; this .label = 1 ; var10000 = MainKt.requestToken(var6); if (var10000 == var4) { return var4; } break ; case 1 : ResultKt.throwOnFailure($result); var10000 = $result; break ; case 2 : ResultKt.throwOnFailure($result); var10000 = $result; break label17; default : throw new IllegalStateException ("call to 'resume' before 'invoke' with coroutine" ); } String token = (String)var10000; Continuation var10001 = (Continuation)this ; this .label = 2 ; var10000 = MainKt.fetchData(token, var10001); if (var10000 == var4) { return var4; } } String fetchData = (String)var10000; System.out.println(fetchData); return Unit.INSTANCE; } public final Continuation create (Object value, Continuation $completion) { return (Continuation)(new <anonymous constructor>($completion)); } public final Object invoke (CoroutineScope p1, Continuation p2) { return ((<undefinedtype>)this .create(p1, p2)).invokeSuspend(Unit.INSTANCE); } public Object invoke (Object p1, Object p2) { return this .invoke((CoroutineScope)p1, (Continuation)p2); } }, 3 , (Object)null ); String var3 = "当前main执行线程为:" + Thread.currentThread(); System.out.println(var3); Continuation var10001 = (Continuation)this ; this .label = 1 ; if (DelayKt.delay(5000L , var10001) == var4) { return var4; } break ; case 1 : ResultKt.throwOnFailure($result); break ; default : throw new IllegalStateException ("call to 'resume' before 'invoke' with coroutine" ); } return Unit.INSTANCE; } public final Continuation create (Object value, Continuation $completion) { Function2 var3 = new <anonymous constructor>($completion); var3.L$0 = value; return (Continuation)var3; } public final Object invoke (CoroutineScope p1, Continuation p2) { return ((<undefinedtype>)this .create(p1, p2)).invokeSuspend(Unit.INSTANCE); } public Object invoke (Object p1, Object p2) { return this .invoke((CoroutineScope)p1, (Continuation)p2); } }, 1 , (Object)null ); } public static void main (String[] args) { main(); } }
可以看出 suspend 的本质其实是回调 + 状态机,只是编译器帮我们做了一些脏活累活,用语法糖帮我们做了 CPS 变换,把一切用回调串了起来。
无栈协程的弊端:
堆栈 :无栈协程没有有完整的调用栈,只是用回调和状态机模拟出协程的行为。染色 :suspend 方法只能被 suspend 方法调用,或被协程上下文调用。这导致当你想要调用一个 suspend 方法,那么你需要把整条调用链路全部重构。这点其实和 javascript 中的 async/await 相似,即函数染色问题。需要注意的是,函数染色问题并不是由 suspend 或 async/await 引入的,实际上在异步回调中就存在。挂起 :从另一个角度看染色问题,可以理解为一个无栈协程无法在任意地方被挂起,因为他的状态/上下文存续依赖于开发者人为在代码中定义。对同步生态兼容差 :如果我们在一个无栈协程中调用阻塞IO,会导致背后的内核线程被阻塞,所以最好需要搭配异步IO一起使用。
无栈协程也有其优点,由于没有真正的调用栈上下文切换,其性能一般较好。
以 go 为例的有栈协程 go 中的协程被称为 goroutine,每个 goroutine 都有自己的调用栈,每个调用栈初始占用非常低,并且可以动态增长和收缩,这意味着开发者可以以很低成本创建大量 goroutine。
看 go 中使用协程的例子:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package mainimport ( "fmt" "time" ) func requestToken (tokenChannel chan <- string ) fmt.Printf("requestToken\n" ) time.Sleep(2 * time.Second) tokenChannel <- "token" } func fetchData (tokenChannel <-chan string ) token := <-tokenChannel fmt.Printf("fetchData\n" ) time.Sleep(2 * time.Second) fmt.Println(fmt.Sprintf("%s:success" , token)) } func main () tokenChannel := make (chan string ) go requestToken(tokenChannel) go fetchData(tokenChannel) fmt.Printf("主线程其他逻辑\n" ) time.Sleep(5 * time.Second) }
这段代码中用 go 关键字启动了两个 goroutine,分别调用两个阻塞方法,并将其结果在 channel 中传递,最终输出结果。
go 在运行时提供了一套调度器,可以将 goroutine 分配到待执行队列中;内核线程从队列中获取并执行 goroutine,如果 goroutine 被阻塞,则会将其挂起,保留它的调用栈和上下文信息到内存中,并调度另一个 goroutine 到该线程执行;当 goroutine 恢复后,go 运行时会将其重新添加到待执行队列中;而这一切对于开发者来说是完全透明的,开发者可以将其当做正常线程使用,并且每个 goroutine 的创建成本非常低。
通过这个 go 代码片段可以看出,有栈协程的使用非常灵活,且对于开发友好:
有栈协程的优点
任意挂起 :由于有运行时的支持,有栈协程可以完整保存调用栈上下文,可以在任意地方被挂起和恢复执行。兼容阻塞IO,开发友好 :同理,由于有运行时的支持,有栈协程调用阻塞IO时,不会阻塞内核线程,而是阻塞有栈协程本身,内核线程可以继续调度其他协程。这使得有栈协程可以几乎完全兼容原有的同步生态,开发者可以像编写同步代码一样,实现异步调用。
java 的虚拟线程 看完了 kotlin 中的无栈协程和 go 中的有栈协程,接下来回到 java 的虚拟线程是什么样的。
jdk21 在 jvm 层面支持了协程原语,并重写了一系列类库以提供了一个重量级特性:虚拟线程。虚拟线程本质上是有栈协程的实现。
我们可以用非常简单的方式启动一个虚拟线程并让它执行一段逻辑,就像 go 中的 go 关键字:
1 2 3 Thread.startVirtualThread(()->{ System.out.println("hello virtual thread" ); });
原有的线程池可以简单地改写为虚拟线程:
1 2 3 4 ExecutorService executorService = Executors.newVirtualThreadPerTaskExecutor();executorService.submit(()->{ System.out.println("hello virtual thread" ); });
我们还可以借助 BlockingQueue 实现和上面 go 中 channel 一样的效果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 package org.example;import java.util.concurrent.BlockingQueue;import java.util.concurrent.ExecutorService;import java.util.concurrent.Executors;import java.util.concurrent.LinkedBlockingQueue;public class Main { static void requestToken (BlockingQueue<String> tokenQueue) { System.out.println("requestToken" ); try { Thread.sleep(2000 ); tokenQueue.put("token" ); } catch (InterruptedException e) { e.printStackTrace(); } } static void fetchData (BlockingQueue<String> tokenQueue) { try { String token = tokenQueue.take(); System.out.println("fetchData" ); Thread.sleep(2000 ); System.out.println(token + ":success" ); } catch (InterruptedException e) { e.printStackTrace(); } } public static void main (String[] args) { BlockingQueue<String> tokenQueue = new LinkedBlockingQueue <>(); ExecutorService executorService = Executors.newVirtualThreadPerTaskExecutor(); executorService.execute(() -> requestToken(tokenQueue)); executorService.execute(() -> fetchData(tokenQueue)); System.out.println("主线程其他逻辑" ); try { Thread.sleep(5000L ); } catch (InterruptedException e) { throw new RuntimeException (e); } finally { executorService.shutdown(); } } }
虚拟线程的一些特性:
虚拟线程是用户线程模式的一种实现,并且相对于内核线程是 n:m 的调度关系。
对于开发者、调试器、代码分析器来说,虚拟线程就是线程,虚拟线程背后的处理是完全透明的。
每个虚拟线程实际上是一个存于堆中的实例;每个虚拟线程有单独的调用栈,这些调用栈也存于堆中。
创建和销毁虚拟线程非常廉价,不需要池化。
虚拟线程中可以调用阻塞IO操作,而它只会阻塞虚拟线程,并不会阻塞虚拟线程背后的载体线程。
虚拟线程支持并兼容原有的所有线程生态,包括 ThreadLocal
但是 java 的虚拟线程并不是完美的,假设有某种场景,使得虚拟线程挂载在载体线程上,而无法卸载(称之为pin),而此时,虚拟线程调用了阻塞IO被阻塞,那么载体线程也将会被阻塞。这实际上是一种正常现象,但是当大量的虚拟线程 pin 住载体线程,就会导致大量内核线程资源被浪费,而其余虚拟线程得不到执行调度,处于饥饿状态。
VirtualThread 体系中的 Continuation 里就定义了虚拟线程可能会被 pin 的几种场景:
1 2 3 4 5 6 7 8 private static Pinned pinnedReason (int reason) { return switch (reason) { case 2 -> Pinned.CRITICAL_SECTION; case 3 -> Pinned.NATIVE; case 4 -> Pinned.MONITOR; default -> throw new AssertionError ("Unknown pinned reason: " + reason); }; }
Pinned.CRITICAL_SECTION:执行临界区代码
对于Java,在执行类加载(classloading)等过程时,就处于“执行临界区代码”的状态
Pinned.NATIVE:执行本地方法
Continuation没有记录本地调用栈,因此不支持在本地方法执行过程中挂起。
Pinned.MONITOR:利用监视器的同步方法
比如 synchronized 就用到了监视器。synchronized 锁的 owner 是当前的载体线程,因此虚拟线程池持锁会导致同步语义混乱。
这的 1、2 两点在大部分开发场景中都不需要特别关注,但是第 3 点需要注意,因为我们无法保证自己依赖的类库中是否存在使用 synchronized 的场景。例如 jdbc 中通过 socket 对数据库进行读写时,就用了 synchronized 来解决并发问题,这会导致你在使用 jdbc 执行到这段逻辑时,阻塞内核线程。所以目前虚拟线程虽然美好,但是迁移工作并不能实现完全无缝。
这个问题已经在 JEP 491 中解决,预计将于 jdk 24 正式推出。
6.总结 在过去,大部分开发者高度依赖 thread - per - request 风格编写代码。在这种模式下,每个方法的每条语句都在同一个线程中依次执行,具有简洁易读、堆栈友好的优点。然而,它在应对 IO 密集型场景时显得力不从心。这本质上源于对线程的滥用,开发者过度依赖内核线程这一重型并发单元来处理问题。
随着对性能需求的提升,部分开发者开始转向异步编程模式。该模式基于事件驱动,处理一个请求的代码块不会在单个线程中从头到尾顺序执行,而是在等待 IO 操作的过程中交错获得线程调度。这种细粒度的调度模式能够支持大量并发操作,避免阻塞过多线程资源。但异步编程也带来了额外的复杂性,开发者不得不放弃一些基本的顺序组合运算符,例如循环和 try/catch。在同步编程中,循环和 try/catch 能方便地实现迭代和异常处理;而在异步编程里,需要使用回调、Promise、async/await 等机制来替代。请求的不同阶段可能在不同线程上执行,这使得像 ThreadLocal 这类依赖线程独立性的机制失效,因为数据无法再简单地与单个线程绑定。此外,将原有的同步代码迁移为异步代码成本高昂,开发者需要付出更多努力才能理解和编写出正确、优雅的异步代码。
为了解决这些问题,协程的概念应运而生。协程本质上是用户线程的一种实现方式,从实现角度可分为无栈协程和有栈协程。
JavaScript、Kotlin 这类编程语言,其常见使用场景包括请求调用、页面渲染和展示等,对性能要求较高。无栈协程在这些场景下具有性能优势,它通常基于状态机实现,切换开销小,能有效提高程序的执行效率,因此这些语言早期多采用无栈协程。
而 Java 作为一门发展了 30 年的编程语言,拥有庞大的同步代码基础。无栈协程由于其实现方式与 Java 现有的同步生态兼容性较差,难以直接融入。Java 需要一种轻量级的用户线程模式,有栈协程正好满足这一需求。有栈协程为每个协程维护独立的栈空间,在实现上更接近传统的线程模型,能够在一定程度上保留同步代码的编程习惯,降低迁移成本,同时也方便开发者进行代码开发和问题排查,这就是虚拟线程/有栈协程对于 Java 的重要意义。
7.参考
jvm为什么需要有栈协程
函数颜色理论
有栈协程与无栈协程
JEP 425: Virtual Threads (Preview) & JEP 444: Virtual Threads
JDK21虚拟线程
JEP 491: Synchronize Virtual Threads without Pinning